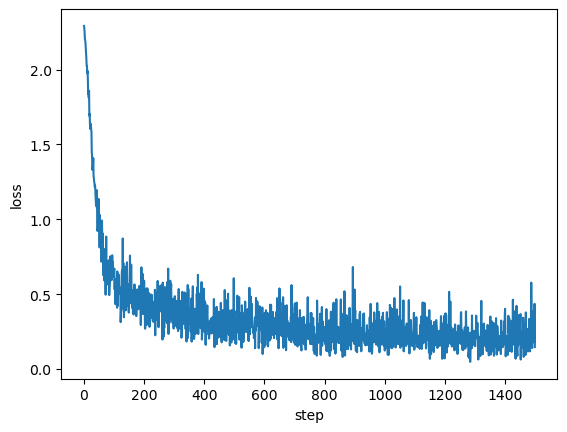
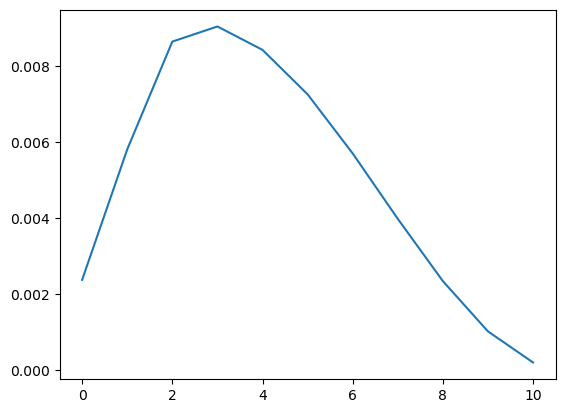
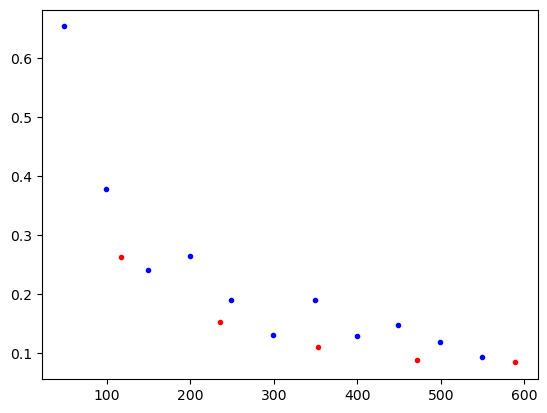
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[23], line 31
20 trainer = Trainer(
21 accelerator="auto",
22 min_epochs=1,
(...)
26 check_val_every_n_epoch=1
27 )
30 tuner = Tuner(trainer)
---> 31 lr_finder = tuner.lr_find(
32 model,
33 datamodule=datamodule,
34 min_lr=1e-6,
35 max_lr=1.0,
36 num_training=100, # number of iterations
37 # attr_name="optimizer.lr",
38 )
39 fig = lr_finder.plot(suggest=True)
40 plt.show()
File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/lightning/pytorch/tuner/tuning.py:180, in Tuner.lr_find(self, model, train_dataloaders, val_dataloaders, dataloaders, datamodule, method, min_lr, max_lr, num_training, mode, early_stop_threshold, update_attr, attr_name)
177 lr_finder_callback._early_exit = True
178 self._trainer.callbacks = [lr_finder_callback] + self._trainer.callbacks
--> 180 self._trainer.fit(model, train_dataloaders, val_dataloaders, datamodule)
182 self._trainer.callbacks = [cb for cb in self._trainer.callbacks if cb is not lr_finder_callback]
184 return lr_finder_callback.optimal_lr
File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/lightning/pytorch/trainer/trainer.py:532, in Trainer.fit(self, model, train_dataloaders, val_dataloaders, datamodule, ckpt_path)
498 def fit(
499 self,
500 model: "pl.LightningModule",
(...)
504 ckpt_path: Optional[_PATH] = None,
505 ) -> None:
506 r"""Runs the full optimization routine.
507
508 Args:
(...)
530
531 """
--> 532 model = _maybe_unwrap_optimized(model)
533 self.strategy._lightning_module = model
534 _verify_strategy_supports_compile(model, self.strategy)
File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/lightning/pytorch/utilities/compile.py:111, in _maybe_unwrap_optimized(model)
109 return model
110 _check_mixed_imports(model)
--> 111 raise TypeError(
112 f"`model` must be a `LightningModule` or `torch._dynamo.OptimizedModule`, got `{type(model).__qualname__}`"
113 )
TypeError: `model` must be a `LightningModule` or `torch._dynamo.OptimizedModule`, got `MLP`