# N_EPOCHS for training debuggging
ITER_MAX = 1
set_seed(42)Seed set to 42# N_EPOCHS for training debuggging
ITER_MAX = 1
set_seed(42)Seed set to 42# reading with pandas
df = pd.read_csv('../data/text/names.txt', header=None, names=['name'])
data = list(df.name)
print("names: ", data[:3])names: ['emma', 'olivia', 'ava']given last n tokens we predict token n+1
s = list("alexandra")
print(s)
bigram = [(x,y) for x, y in zip(s, s[1:])]
print(bigram)
trigram = [ (x,y,z) for x, y, z in zip(s, s[1:], s[2:])]
print(trigram)['a', 'l', 'e', 'x', 'a', 'n', 'd', 'r', 'a']
[('a', 'l'), ('l', 'e'), ('e', 'x'), ('x', 'a'), ('a', 'n'), ('n', 'd'), ('d', 'r'), ('r', 'a')]
[('a', 'l', 'e'), ('l', 'e', 'x'), ('e', 'x', 'a'), ('x', 'a', 'n'), ('a', 'n', 'd'), ('n', 'd', 'r'), ('d', 'r', 'a')]# reading directly in plain python
lines = []
with open('../data/text/tiny_shakespeare.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
if line.strip():
# only append non blank lines
lines.append(line)
# add sentence tokens
# data = [['<bos>'] +list(line.strip()) + ['<eos>'] for line in lines]
# data = [list(line.strip()) for line in lines]
data = [list(line) for line in lines]
print("data: ", data[:3])data: [['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n'], ['B', 'e', 'f', 'o', 'r', 'e', ' ', 'w', 'e', ' ', 'p', 'r', 'o', 'c', 'e', 'e', 'd', ' ', 'a', 'n', 'y', ' ', 'f', 'u', 'r', 't', 'h', 'e', 'r', ',', ' ', 'h', 'e', 'a', 'r', ' ', 'm', 'e', ' ', 's', 'p', 'e', 'a', 'k', '.', '\n'], ['A', 'l', 'l', ':', '\n']]def make_dataset(
words:List[str], # data is a list of sentences which are a list of words
v:Vocab,# vocabulary class for mapping words to indices
verbose:bool=False, # print debug info
context_length=3 # number of words/tokens to use as context
):
X = []
y = []
for word in words:
s = list(word)
if verbose:
print('row: ', s)
# init prefix with padding while len < context_length
for i in range(context_length-1):
sequence = v.stoi(s[:i+1])
pad_len = context_length - len(sequence)
pad = [v.stoi("<pad>")] * pad_len
X.append(pad + sequence)
y.append(v.stoi(s[i+1]))
if verbose:
print(["<pad>"]+ s[:i+1], s[i+1])
# for length seq = context_length
i = 0
while i < (len(s) - context_length):
X.append(v.stoi(s[i:context_length+i]))
y.append(v.stoi(s[i+context_length]))
if verbose:
print(s[i:context_length+i], s[i+context_length])
i += 1
return torch.tensor(X),torch.tensor(y)for each row in the dataset we expand all the combinations of ngrams
v = Vocab(data_path='../data/text/tiny_shakespeare.txt', specials=['<unk>','<pad>'])
print("vocabulary: ", v.vocabulary)
print("vocabulary size: ", len(v))[21:05:26] INFO - Vocab: read text filevocabulary: ['\n', ' ', '!', '$', '&', "'", ',', '-', '.', '3', ':', ';', '<pad>', '<unk>', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
vocabulary size: 67CONTEXT_LEN = 3
X, y = make_dataset(data[:80], v, verbose=True, context_length=CONTEXT_LEN)
print("X: ", X.shape, "y:", y.shape)row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['B', 'e', 'f', 'o', 'r', 'e', ' ', 'w', 'e', ' ', 'p', 'r', 'o', 'c', 'e', 'e', 'd', ' ', 'a', 'n', 'y', ' ', 'f', 'u', 'r', 't', 'h', 'e', 'r', ',', ' ', 'h', 'e', 'a', 'r', ' ', 'm', 'e', ' ', 's', 'p', 'e', 'a', 'k', '.', '\n']
['<pad>', 'B'] e
['<pad>', 'B', 'e'] f
['B', 'e', 'f'] o
['e', 'f', 'o'] r
['f', 'o', 'r'] e
['o', 'r', 'e']
['r', 'e', ' '] w
['e', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] p
['e', ' ', 'p'] r
[' ', 'p', 'r'] o
['p', 'r', 'o'] c
['r', 'o', 'c'] e
['o', 'c', 'e'] e
['c', 'e', 'e'] d
['e', 'e', 'd']
['e', 'd', ' '] a
['d', ' ', 'a'] n
[' ', 'a', 'n'] y
['a', 'n', 'y']
['n', 'y', ' '] f
['y', ' ', 'f'] u
[' ', 'f', 'u'] r
['f', 'u', 'r'] t
['u', 'r', 't'] h
['r', 't', 'h'] e
['t', 'h', 'e'] r
['h', 'e', 'r'] ,
['e', 'r', ',']
['r', ',', ' '] h
[',', ' ', 'h'] e
[' ', 'h', 'e'] a
['h', 'e', 'a'] r
['e', 'a', 'r']
['a', 'r', ' '] m
['r', ' ', 'm'] e
[' ', 'm', 'e']
['m', 'e', ' '] s
['e', ' ', 's'] p
[' ', 's', 'p'] e
['s', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k'] .
['a', 'k', '.']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['S', 'p', 'e', 'a', 'k', ',', ' ', 's', 'p', 'e', 'a', 'k', '.', '\n']
['<pad>', 'S'] p
['<pad>', 'S', 'p'] e
['S', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k'] ,
['a', 'k', ',']
['k', ',', ' '] s
[',', ' ', 's'] p
[' ', 's', 'p'] e
['s', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k'] .
['a', 'k', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['Y', 'o', 'u', ' ', 'a', 'r', 'e', ' ', 'a', 'l', 'l', ' ', 'r', 'e', 's', 'o', 'l', 'v', 'e', 'd', ' ', 'r', 'a', 't', 'h', 'e', 'r', ' ', 't', 'o', ' ', 'd', 'i', 'e', ' ', 't', 'h', 'a', 'n', ' ', 't', 'o', ' ', 'f', 'a', 'm', 'i', 's', 'h', '?', '\n']
['<pad>', 'Y'] o
['<pad>', 'Y', 'o'] u
['Y', 'o', 'u']
['o', 'u', ' '] a
['u', ' ', 'a'] r
[' ', 'a', 'r'] e
['a', 'r', 'e']
['r', 'e', ' '] a
['e', ' ', 'a'] l
[' ', 'a', 'l'] l
['a', 'l', 'l']
['l', 'l', ' '] r
['l', ' ', 'r'] e
[' ', 'r', 'e'] s
['r', 'e', 's'] o
['e', 's', 'o'] l
['s', 'o', 'l'] v
['o', 'l', 'v'] e
['l', 'v', 'e'] d
['v', 'e', 'd']
['e', 'd', ' '] r
['d', ' ', 'r'] a
[' ', 'r', 'a'] t
['r', 'a', 't'] h
['a', 't', 'h'] e
['t', 'h', 'e'] r
['h', 'e', 'r']
['e', 'r', ' '] t
['r', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] d
['o', ' ', 'd'] i
[' ', 'd', 'i'] e
['d', 'i', 'e']
['i', 'e', ' '] t
['e', ' ', 't'] h
[' ', 't', 'h'] a
['t', 'h', 'a'] n
['h', 'a', 'n']
['a', 'n', ' '] t
['n', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] f
['o', ' ', 'f'] a
[' ', 'f', 'a'] m
['f', 'a', 'm'] i
['a', 'm', 'i'] s
['m', 'i', 's'] h
['i', 's', 'h'] ?
['s', 'h', '?']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['R', 'e', 's', 'o', 'l', 'v', 'e', 'd', '.', ' ', 'r', 'e', 's', 'o', 'l', 'v', 'e', 'd', '.', '\n']
['<pad>', 'R'] e
['<pad>', 'R', 'e'] s
['R', 'e', 's'] o
['e', 's', 'o'] l
['s', 'o', 'l'] v
['o', 'l', 'v'] e
['l', 'v', 'e'] d
['v', 'e', 'd'] .
['e', 'd', '.']
['d', '.', ' '] r
['.', ' ', 'r'] e
[' ', 'r', 'e'] s
['r', 'e', 's'] o
['e', 's', 'o'] l
['s', 'o', 'l'] v
['o', 'l', 'v'] e
['l', 'v', 'e'] d
['v', 'e', 'd'] .
['e', 'd', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['F', 'i', 'r', 's', 't', ',', ' ', 'y', 'o', 'u', ' ', 'k', 'n', 'o', 'w', ' ', 'C', 'a', 'i', 'u', 's', ' ', 'M', 'a', 'r', 'c', 'i', 'u', 's', ' ', 'i', 's', ' ', 'c', 'h', 'i', 'e', 'f', ' ', 'e', 'n', 'e', 'm', 'y', ' ', 't', 'o', ' ', 't', 'h', 'e', ' ', 'p', 'e', 'o', 'p', 'l', 'e', '.', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't'] ,
['s', 't', ',']
['t', ',', ' '] y
[',', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
['o', 'u', ' '] k
['u', ' ', 'k'] n
[' ', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w']
['o', 'w', ' '] C
['w', ' ', 'C'] a
[' ', 'C', 'a'] i
['C', 'a', 'i'] u
['a', 'i', 'u'] s
['i', 'u', 's']
['u', 's', ' '] M
['s', ' ', 'M'] a
[' ', 'M', 'a'] r
['M', 'a', 'r'] c
['a', 'r', 'c'] i
['r', 'c', 'i'] u
['c', 'i', 'u'] s
['i', 'u', 's']
['u', 's', ' '] i
['s', ' ', 'i'] s
[' ', 'i', 's']
['i', 's', ' '] c
['s', ' ', 'c'] h
[' ', 'c', 'h'] i
['c', 'h', 'i'] e
['h', 'i', 'e'] f
['i', 'e', 'f']
['e', 'f', ' '] e
['f', ' ', 'e'] n
[' ', 'e', 'n'] e
['e', 'n', 'e'] m
['n', 'e', 'm'] y
['e', 'm', 'y']
['m', 'y', ' '] t
['y', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] p
['e', ' ', 'p'] e
[' ', 'p', 'e'] o
['p', 'e', 'o'] p
['e', 'o', 'p'] l
['o', 'p', 'l'] e
['p', 'l', 'e'] .
['l', 'e', '.']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['W', 'e', ' ', 'k', 'n', 'o', 'w', "'", 't', ',', ' ', 'w', 'e', ' ', 'k', 'n', 'o', 'w', "'", 't', '.', '\n']
['<pad>', 'W'] e
['<pad>', 'W', 'e']
['W', 'e', ' '] k
['e', ' ', 'k'] n
[' ', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w'] '
['o', 'w', "'"] t
['w', "'", 't'] ,
["'", 't', ',']
['t', ',', ' '] w
[',', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] k
['e', ' ', 'k'] n
[' ', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w'] '
['o', 'w', "'"] t
['w', "'", 't'] .
["'", 't', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['L', 'e', 't', ' ', 'u', 's', ' ', 'k', 'i', 'l', 'l', ' ', 'h', 'i', 'm', ',', ' ', 'a', 'n', 'd', ' ', 'w', 'e', "'", 'l', 'l', ' ', 'h', 'a', 'v', 'e', ' ', 'c', 'o', 'r', 'n', ' ', 'a', 't', ' ', 'o', 'u', 'r', ' ', 'o', 'w', 'n', ' ', 'p', 'r', 'i', 'c', 'e', '.', '\n']
['<pad>', 'L'] e
['<pad>', 'L', 'e'] t
['L', 'e', 't']
['e', 't', ' '] u
['t', ' ', 'u'] s
[' ', 'u', 's']
['u', 's', ' '] k
['s', ' ', 'k'] i
[' ', 'k', 'i'] l
['k', 'i', 'l'] l
['i', 'l', 'l']
['l', 'l', ' '] h
['l', ' ', 'h'] i
[' ', 'h', 'i'] m
['h', 'i', 'm'] ,
['i', 'm', ',']
['m', ',', ' '] a
[',', ' ', 'a'] n
[' ', 'a', 'n'] d
['a', 'n', 'd']
['n', 'd', ' '] w
['d', ' ', 'w'] e
[' ', 'w', 'e'] '
['w', 'e', "'"] l
['e', "'", 'l'] l
["'", 'l', 'l']
['l', 'l', ' '] h
['l', ' ', 'h'] a
[' ', 'h', 'a'] v
['h', 'a', 'v'] e
['a', 'v', 'e']
['v', 'e', ' '] c
['e', ' ', 'c'] o
[' ', 'c', 'o'] r
['c', 'o', 'r'] n
['o', 'r', 'n']
['r', 'n', ' '] a
['n', ' ', 'a'] t
[' ', 'a', 't']
['a', 't', ' '] o
['t', ' ', 'o'] u
[' ', 'o', 'u'] r
['o', 'u', 'r']
['u', 'r', ' '] o
['r', ' ', 'o'] w
[' ', 'o', 'w'] n
['o', 'w', 'n']
['w', 'n', ' '] p
['n', ' ', 'p'] r
[' ', 'p', 'r'] i
['p', 'r', 'i'] c
['r', 'i', 'c'] e
['i', 'c', 'e'] .
['c', 'e', '.']
row: ['I', 's', "'", 't', ' ', 'a', ' ', 'v', 'e', 'r', 'd', 'i', 'c', 't', '?', '\n']
['<pad>', 'I'] s
['<pad>', 'I', 's'] '
['I', 's', "'"] t
['s', "'", 't']
["'", 't', ' '] a
['t', ' ', 'a']
[' ', 'a', ' '] v
['a', ' ', 'v'] e
[' ', 'v', 'e'] r
['v', 'e', 'r'] d
['e', 'r', 'd'] i
['r', 'd', 'i'] c
['d', 'i', 'c'] t
['i', 'c', 't'] ?
['c', 't', '?']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['N', 'o', ' ', 'm', 'o', 'r', 'e', ' ', 't', 'a', 'l', 'k', 'i', 'n', 'g', ' ', 'o', 'n', "'", 't', ';', ' ', 'l', 'e', 't', ' ', 'i', 't', ' ', 'b', 'e', ' ', 'd', 'o', 'n', 'e', ':', ' ', 'a', 'w', 'a', 'y', ',', ' ', 'a', 'w', 'a', 'y', '!', '\n']
['<pad>', 'N'] o
['<pad>', 'N', 'o']
['N', 'o', ' '] m
['o', ' ', 'm'] o
[' ', 'm', 'o'] r
['m', 'o', 'r'] e
['o', 'r', 'e']
['r', 'e', ' '] t
['e', ' ', 't'] a
[' ', 't', 'a'] l
['t', 'a', 'l'] k
['a', 'l', 'k'] i
['l', 'k', 'i'] n
['k', 'i', 'n'] g
['i', 'n', 'g']
['n', 'g', ' '] o
['g', ' ', 'o'] n
[' ', 'o', 'n'] '
['o', 'n', "'"] t
['n', "'", 't'] ;
["'", 't', ';']
['t', ';', ' '] l
[';', ' ', 'l'] e
[' ', 'l', 'e'] t
['l', 'e', 't']
['e', 't', ' '] i
['t', ' ', 'i'] t
[' ', 'i', 't']
['i', 't', ' '] b
['t', ' ', 'b'] e
[' ', 'b', 'e']
['b', 'e', ' '] d
['e', ' ', 'd'] o
[' ', 'd', 'o'] n
['d', 'o', 'n'] e
['o', 'n', 'e'] :
['n', 'e', ':']
['e', ':', ' '] a
[':', ' ', 'a'] w
[' ', 'a', 'w'] a
['a', 'w', 'a'] y
['w', 'a', 'y'] ,
['a', 'y', ',']
['y', ',', ' '] a
[',', ' ', 'a'] w
[' ', 'a', 'w'] a
['a', 'w', 'a'] y
['w', 'a', 'y'] !
['a', 'y', '!']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['O', 'n', 'e', ' ', 'w', 'o', 'r', 'd', ',', ' ', 'g', 'o', 'o', 'd', ' ', 'c', 'i', 't', 'i', 'z', 'e', 'n', 's', '.', '\n']
['<pad>', 'O'] n
['<pad>', 'O', 'n'] e
['O', 'n', 'e']
['n', 'e', ' '] w
['e', ' ', 'w'] o
[' ', 'w', 'o'] r
['w', 'o', 'r'] d
['o', 'r', 'd'] ,
['r', 'd', ',']
['d', ',', ' '] g
[',', ' ', 'g'] o
[' ', 'g', 'o'] o
['g', 'o', 'o'] d
['o', 'o', 'd']
['o', 'd', ' '] c
['d', ' ', 'c'] i
[' ', 'c', 'i'] t
['c', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] s
['e', 'n', 's'] .
['n', 's', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['W', 'e', ' ', 'a', 'r', 'e', ' ', 'a', 'c', 'c', 'o', 'u', 'n', 't', 'e', 'd', ' ', 'p', 'o', 'o', 'r', ' ', 'c', 'i', 't', 'i', 'z', 'e', 'n', 's', ',', ' ', 't', 'h', 'e', ' ', 'p', 'a', 't', 'r', 'i', 'c', 'i', 'a', 'n', 's', ' ', 'g', 'o', 'o', 'd', '.', '\n']
['<pad>', 'W'] e
['<pad>', 'W', 'e']
['W', 'e', ' '] a
['e', ' ', 'a'] r
[' ', 'a', 'r'] e
['a', 'r', 'e']
['r', 'e', ' '] a
['e', ' ', 'a'] c
[' ', 'a', 'c'] c
['a', 'c', 'c'] o
['c', 'c', 'o'] u
['c', 'o', 'u'] n
['o', 'u', 'n'] t
['u', 'n', 't'] e
['n', 't', 'e'] d
['t', 'e', 'd']
['e', 'd', ' '] p
['d', ' ', 'p'] o
[' ', 'p', 'o'] o
['p', 'o', 'o'] r
['o', 'o', 'r']
['o', 'r', ' '] c
['r', ' ', 'c'] i
[' ', 'c', 'i'] t
['c', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] s
['e', 'n', 's'] ,
['n', 's', ',']
['s', ',', ' '] t
[',', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] p
['e', ' ', 'p'] a
[' ', 'p', 'a'] t
['p', 'a', 't'] r
['a', 't', 'r'] i
['t', 'r', 'i'] c
['r', 'i', 'c'] i
['i', 'c', 'i'] a
['c', 'i', 'a'] n
['i', 'a', 'n'] s
['a', 'n', 's']
['n', 's', ' '] g
['s', ' ', 'g'] o
[' ', 'g', 'o'] o
['g', 'o', 'o'] d
['o', 'o', 'd'] .
['o', 'd', '.']
row: ['W', 'h', 'a', 't', ' ', 'a', 'u', 't', 'h', 'o', 'r', 'i', 't', 'y', ' ', 's', 'u', 'r', 'f', 'e', 'i', 't', 's', ' ', 'o', 'n', ' ', 'w', 'o', 'u', 'l', 'd', ' ', 'r', 'e', 'l', 'i', 'e', 'v', 'e', ' ', 'u', 's', ':', ' ', 'i', 'f', ' ', 't', 'h', 'e', 'y', '\n']
['<pad>', 'W'] h
['<pad>', 'W', 'h'] a
['W', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] a
['t', ' ', 'a'] u
[' ', 'a', 'u'] t
['a', 'u', 't'] h
['u', 't', 'h'] o
['t', 'h', 'o'] r
['h', 'o', 'r'] i
['o', 'r', 'i'] t
['r', 'i', 't'] y
['i', 't', 'y']
['t', 'y', ' '] s
['y', ' ', 's'] u
[' ', 's', 'u'] r
['s', 'u', 'r'] f
['u', 'r', 'f'] e
['r', 'f', 'e'] i
['f', 'e', 'i'] t
['e', 'i', 't'] s
['i', 't', 's']
['t', 's', ' '] o
['s', ' ', 'o'] n
[' ', 'o', 'n']
['o', 'n', ' '] w
['n', ' ', 'w'] o
[' ', 'w', 'o'] u
['w', 'o', 'u'] l
['o', 'u', 'l'] d
['u', 'l', 'd']
['l', 'd', ' '] r
['d', ' ', 'r'] e
[' ', 'r', 'e'] l
['r', 'e', 'l'] i
['e', 'l', 'i'] e
['l', 'i', 'e'] v
['i', 'e', 'v'] e
['e', 'v', 'e']
['v', 'e', ' '] u
['e', ' ', 'u'] s
[' ', 'u', 's'] :
['u', 's', ':']
['s', ':', ' '] i
[':', ' ', 'i'] f
[' ', 'i', 'f']
['i', 'f', ' '] t
['f', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] y
['h', 'e', 'y']
row: ['w', 'o', 'u', 'l', 'd', ' ', 'y', 'i', 'e', 'l', 'd', ' ', 'u', 's', ' ', 'b', 'u', 't', ' ', 't', 'h', 'e', ' ', 's', 'u', 'p', 'e', 'r', 'f', 'l', 'u', 'i', 't', 'y', ',', ' ', 'w', 'h', 'i', 'l', 'e', ' ', 'i', 't', ' ', 'w', 'e', 'r', 'e', '\n']
['<pad>', 'w'] o
['<pad>', 'w', 'o'] u
['w', 'o', 'u'] l
['o', 'u', 'l'] d
['u', 'l', 'd']
['l', 'd', ' '] y
['d', ' ', 'y'] i
[' ', 'y', 'i'] e
['y', 'i', 'e'] l
['i', 'e', 'l'] d
['e', 'l', 'd']
['l', 'd', ' '] u
['d', ' ', 'u'] s
[' ', 'u', 's']
['u', 's', ' '] b
['s', ' ', 'b'] u
[' ', 'b', 'u'] t
['b', 'u', 't']
['u', 't', ' '] t
['t', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] s
['e', ' ', 's'] u
[' ', 's', 'u'] p
['s', 'u', 'p'] e
['u', 'p', 'e'] r
['p', 'e', 'r'] f
['e', 'r', 'f'] l
['r', 'f', 'l'] u
['f', 'l', 'u'] i
['l', 'u', 'i'] t
['u', 'i', 't'] y
['i', 't', 'y'] ,
['t', 'y', ',']
['y', ',', ' '] w
[',', ' ', 'w'] h
[' ', 'w', 'h'] i
['w', 'h', 'i'] l
['h', 'i', 'l'] e
['i', 'l', 'e']
['l', 'e', ' '] i
['e', ' ', 'i'] t
[' ', 'i', 't']
['i', 't', ' '] w
['t', ' ', 'w'] e
[' ', 'w', 'e'] r
['w', 'e', 'r'] e
['e', 'r', 'e']
row: ['w', 'h', 'o', 'l', 'e', 's', 'o', 'm', 'e', ',', ' ', 'w', 'e', ' ', 'm', 'i', 'g', 'h', 't', ' ', 'g', 'u', 'e', 's', 's', ' ', 't', 'h', 'e', 'y', ' ', 'r', 'e', 'l', 'i', 'e', 'v', 'e', 'd', ' ', 'u', 's', ' ', 'h', 'u', 'm', 'a', 'n', 'e', 'l', 'y', ';', '\n']
['<pad>', 'w'] h
['<pad>', 'w', 'h'] o
['w', 'h', 'o'] l
['h', 'o', 'l'] e
['o', 'l', 'e'] s
['l', 'e', 's'] o
['e', 's', 'o'] m
['s', 'o', 'm'] e
['o', 'm', 'e'] ,
['m', 'e', ',']
['e', ',', ' '] w
[',', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] m
['e', ' ', 'm'] i
[' ', 'm', 'i'] g
['m', 'i', 'g'] h
['i', 'g', 'h'] t
['g', 'h', 't']
['h', 't', ' '] g
['t', ' ', 'g'] u
[' ', 'g', 'u'] e
['g', 'u', 'e'] s
['u', 'e', 's'] s
['e', 's', 's']
['s', 's', ' '] t
['s', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] y
['h', 'e', 'y']
['e', 'y', ' '] r
['y', ' ', 'r'] e
[' ', 'r', 'e'] l
['r', 'e', 'l'] i
['e', 'l', 'i'] e
['l', 'i', 'e'] v
['i', 'e', 'v'] e
['e', 'v', 'e'] d
['v', 'e', 'd']
['e', 'd', ' '] u
['d', ' ', 'u'] s
[' ', 'u', 's']
['u', 's', ' '] h
['s', ' ', 'h'] u
[' ', 'h', 'u'] m
['h', 'u', 'm'] a
['u', 'm', 'a'] n
['m', 'a', 'n'] e
['a', 'n', 'e'] l
['n', 'e', 'l'] y
['e', 'l', 'y'] ;
['l', 'y', ';']
row: ['b', 'u', 't', ' ', 't', 'h', 'e', 'y', ' ', 't', 'h', 'i', 'n', 'k', ' ', 'w', 'e', ' ', 'a', 'r', 'e', ' ', 't', 'o', 'o', ' ', 'd', 'e', 'a', 'r', ':', ' ', 't', 'h', 'e', ' ', 'l', 'e', 'a', 'n', 'n', 'e', 's', 's', ' ', 't', 'h', 'a', 't', '\n']
['<pad>', 'b'] u
['<pad>', 'b', 'u'] t
['b', 'u', 't']
['u', 't', ' '] t
['t', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] y
['h', 'e', 'y']
['e', 'y', ' '] t
['y', ' ', 't'] h
[' ', 't', 'h'] i
['t', 'h', 'i'] n
['h', 'i', 'n'] k
['i', 'n', 'k']
['n', 'k', ' '] w
['k', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] a
['e', ' ', 'a'] r
[' ', 'a', 'r'] e
['a', 'r', 'e']
['r', 'e', ' '] t
['e', ' ', 't'] o
[' ', 't', 'o'] o
['t', 'o', 'o']
['o', 'o', ' '] d
['o', ' ', 'd'] e
[' ', 'd', 'e'] a
['d', 'e', 'a'] r
['e', 'a', 'r'] :
['a', 'r', ':']
['r', ':', ' '] t
[':', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] l
['e', ' ', 'l'] e
[' ', 'l', 'e'] a
['l', 'e', 'a'] n
['e', 'a', 'n'] n
['a', 'n', 'n'] e
['n', 'n', 'e'] s
['n', 'e', 's'] s
['e', 's', 's']
['s', 's', ' '] t
['s', ' ', 't'] h
[' ', 't', 'h'] a
['t', 'h', 'a'] t
['h', 'a', 't']
row: ['a', 'f', 'f', 'l', 'i', 'c', 't', 's', ' ', 'u', 's', ',', ' ', 't', 'h', 'e', ' ', 'o', 'b', 'j', 'e', 'c', 't', ' ', 'o', 'f', ' ', 'o', 'u', 'r', ' ', 'm', 'i', 's', 'e', 'r', 'y', ',', ' ', 'i', 's', ' ', 'a', 's', ' ', 'a', 'n', '\n']
['<pad>', 'a'] f
['<pad>', 'a', 'f'] f
['a', 'f', 'f'] l
['f', 'f', 'l'] i
['f', 'l', 'i'] c
['l', 'i', 'c'] t
['i', 'c', 't'] s
['c', 't', 's']
['t', 's', ' '] u
['s', ' ', 'u'] s
[' ', 'u', 's'] ,
['u', 's', ',']
['s', ',', ' '] t
[',', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] o
['e', ' ', 'o'] b
[' ', 'o', 'b'] j
['o', 'b', 'j'] e
['b', 'j', 'e'] c
['j', 'e', 'c'] t
['e', 'c', 't']
['c', 't', ' '] o
['t', ' ', 'o'] f
[' ', 'o', 'f']
['o', 'f', ' '] o
['f', ' ', 'o'] u
[' ', 'o', 'u'] r
['o', 'u', 'r']
['u', 'r', ' '] m
['r', ' ', 'm'] i
[' ', 'm', 'i'] s
['m', 'i', 's'] e
['i', 's', 'e'] r
['s', 'e', 'r'] y
['e', 'r', 'y'] ,
['r', 'y', ',']
['y', ',', ' '] i
[',', ' ', 'i'] s
[' ', 'i', 's']
['i', 's', ' '] a
['s', ' ', 'a'] s
[' ', 'a', 's']
['a', 's', ' '] a
['s', ' ', 'a'] n
[' ', 'a', 'n']
row: ['i', 'n', 'v', 'e', 'n', 't', 'o', 'r', 'y', ' ', 't', 'o', ' ', 'p', 'a', 'r', 't', 'i', 'c', 'u', 'l', 'a', 'r', 'i', 's', 'e', ' ', 't', 'h', 'e', 'i', 'r', ' ', 'a', 'b', 'u', 'n', 'd', 'a', 'n', 'c', 'e', ';', ' ', 'o', 'u', 'r', '\n']
['<pad>', 'i'] n
['<pad>', 'i', 'n'] v
['i', 'n', 'v'] e
['n', 'v', 'e'] n
['v', 'e', 'n'] t
['e', 'n', 't'] o
['n', 't', 'o'] r
['t', 'o', 'r'] y
['o', 'r', 'y']
['r', 'y', ' '] t
['y', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] p
['o', ' ', 'p'] a
[' ', 'p', 'a'] r
['p', 'a', 'r'] t
['a', 'r', 't'] i
['r', 't', 'i'] c
['t', 'i', 'c'] u
['i', 'c', 'u'] l
['c', 'u', 'l'] a
['u', 'l', 'a'] r
['l', 'a', 'r'] i
['a', 'r', 'i'] s
['r', 'i', 's'] e
['i', 's', 'e']
['s', 'e', ' '] t
['e', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] i
['h', 'e', 'i'] r
['e', 'i', 'r']
['i', 'r', ' '] a
['r', ' ', 'a'] b
[' ', 'a', 'b'] u
['a', 'b', 'u'] n
['b', 'u', 'n'] d
['u', 'n', 'd'] a
['n', 'd', 'a'] n
['d', 'a', 'n'] c
['a', 'n', 'c'] e
['n', 'c', 'e'] ;
['c', 'e', ';']
['e', ';', ' '] o
[';', ' ', 'o'] u
[' ', 'o', 'u'] r
['o', 'u', 'r']
row: ['s', 'u', 'f', 'f', 'e', 'r', 'a', 'n', 'c', 'e', ' ', 'i', 's', ' ', 'a', ' ', 'g', 'a', 'i', 'n', ' ', 't', 'o', ' ', 't', 'h', 'e', 'm', ' ', 'L', 'e', 't', ' ', 'u', 's', ' ', 'r', 'e', 'v', 'e', 'n', 'g', 'e', ' ', 't', 'h', 'i', 's', ' ', 'w', 'i', 't', 'h', '\n']
['<pad>', 's'] u
['<pad>', 's', 'u'] f
['s', 'u', 'f'] f
['u', 'f', 'f'] e
['f', 'f', 'e'] r
['f', 'e', 'r'] a
['e', 'r', 'a'] n
['r', 'a', 'n'] c
['a', 'n', 'c'] e
['n', 'c', 'e']
['c', 'e', ' '] i
['e', ' ', 'i'] s
[' ', 'i', 's']
['i', 's', ' '] a
['s', ' ', 'a']
[' ', 'a', ' '] g
['a', ' ', 'g'] a
[' ', 'g', 'a'] i
['g', 'a', 'i'] n
['a', 'i', 'n']
['i', 'n', ' '] t
['n', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] m
['h', 'e', 'm']
['e', 'm', ' '] L
['m', ' ', 'L'] e
[' ', 'L', 'e'] t
['L', 'e', 't']
['e', 't', ' '] u
['t', ' ', 'u'] s
[' ', 'u', 's']
['u', 's', ' '] r
['s', ' ', 'r'] e
[' ', 'r', 'e'] v
['r', 'e', 'v'] e
['e', 'v', 'e'] n
['v', 'e', 'n'] g
['e', 'n', 'g'] e
['n', 'g', 'e']
['g', 'e', ' '] t
['e', ' ', 't'] h
[' ', 't', 'h'] i
['t', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] w
['s', ' ', 'w'] i
[' ', 'w', 'i'] t
['w', 'i', 't'] h
['i', 't', 'h']
row: ['o', 'u', 'r', ' ', 'p', 'i', 'k', 'e', 's', ',', ' ', 'e', 'r', 'e', ' ', 'w', 'e', ' ', 'b', 'e', 'c', 'o', 'm', 'e', ' ', 'r', 'a', 'k', 'e', 's', ':', ' ', 'f', 'o', 'r', ' ', 't', 'h', 'e', ' ', 'g', 'o', 'd', 's', ' ', 'k', 'n', 'o', 'w', ' ', 'I', '\n']
['<pad>', 'o'] u
['<pad>', 'o', 'u'] r
['o', 'u', 'r']
['u', 'r', ' '] p
['r', ' ', 'p'] i
[' ', 'p', 'i'] k
['p', 'i', 'k'] e
['i', 'k', 'e'] s
['k', 'e', 's'] ,
['e', 's', ',']
['s', ',', ' '] e
[',', ' ', 'e'] r
[' ', 'e', 'r'] e
['e', 'r', 'e']
['r', 'e', ' '] w
['e', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] b
['e', ' ', 'b'] e
[' ', 'b', 'e'] c
['b', 'e', 'c'] o
['e', 'c', 'o'] m
['c', 'o', 'm'] e
['o', 'm', 'e']
['m', 'e', ' '] r
['e', ' ', 'r'] a
[' ', 'r', 'a'] k
['r', 'a', 'k'] e
['a', 'k', 'e'] s
['k', 'e', 's'] :
['e', 's', ':']
['s', ':', ' '] f
[':', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r']
['o', 'r', ' '] t
['r', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] g
['e', ' ', 'g'] o
[' ', 'g', 'o'] d
['g', 'o', 'd'] s
['o', 'd', 's']
['d', 's', ' '] k
['s', ' ', 'k'] n
[' ', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w']
['o', 'w', ' '] I
['w', ' ', 'I']
row: ['s', 'p', 'e', 'a', 'k', ' ', 't', 'h', 'i', 's', ' ', 'i', 'n', ' ', 'h', 'u', 'n', 'g', 'e', 'r', ' ', 'f', 'o', 'r', ' ', 'b', 'r', 'e', 'a', 'd', ',', ' ', 'n', 'o', 't', ' ', 'i', 'n', ' ', 't', 'h', 'i', 'r', 's', 't', ' ', 'f', 'o', 'r', ' ', 'r', 'e', 'v', 'e', 'n', 'g', 'e', '.', '\n']
['<pad>', 's'] p
['<pad>', 's', 'p'] e
['s', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k']
['a', 'k', ' '] t
['k', ' ', 't'] h
[' ', 't', 'h'] i
['t', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] i
['s', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] h
['n', ' ', 'h'] u
[' ', 'h', 'u'] n
['h', 'u', 'n'] g
['u', 'n', 'g'] e
['n', 'g', 'e'] r
['g', 'e', 'r']
['e', 'r', ' '] f
['r', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r']
['o', 'r', ' '] b
['r', ' ', 'b'] r
[' ', 'b', 'r'] e
['b', 'r', 'e'] a
['r', 'e', 'a'] d
['e', 'a', 'd'] ,
['a', 'd', ',']
['d', ',', ' '] n
[',', ' ', 'n'] o
[' ', 'n', 'o'] t
['n', 'o', 't']
['o', 't', ' '] i
['t', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] t
['n', ' ', 't'] h
[' ', 't', 'h'] i
['t', 'h', 'i'] r
['h', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] f
['t', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r']
['o', 'r', ' '] r
['r', ' ', 'r'] e
[' ', 'r', 'e'] v
['r', 'e', 'v'] e
['e', 'v', 'e'] n
['v', 'e', 'n'] g
['e', 'n', 'g'] e
['n', 'g', 'e'] .
['g', 'e', '.']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['W', 'o', 'u', 'l', 'd', ' ', 'y', 'o', 'u', ' ', 'p', 'r', 'o', 'c', 'e', 'e', 'd', ' ', 'e', 's', 'p', 'e', 'c', 'i', 'a', 'l', 'l', 'y', ' ', 'a', 'g', 'a', 'i', 'n', 's', 't', ' ', 'C', 'a', 'i', 'u', 's', ' ', 'M', 'a', 'r', 'c', 'i', 'u', 's', '?', '\n']
['<pad>', 'W'] o
['<pad>', 'W', 'o'] u
['W', 'o', 'u'] l
['o', 'u', 'l'] d
['u', 'l', 'd']
['l', 'd', ' '] y
['d', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
['o', 'u', ' '] p
['u', ' ', 'p'] r
[' ', 'p', 'r'] o
['p', 'r', 'o'] c
['r', 'o', 'c'] e
['o', 'c', 'e'] e
['c', 'e', 'e'] d
['e', 'e', 'd']
['e', 'd', ' '] e
['d', ' ', 'e'] s
[' ', 'e', 's'] p
['e', 's', 'p'] e
['s', 'p', 'e'] c
['p', 'e', 'c'] i
['e', 'c', 'i'] a
['c', 'i', 'a'] l
['i', 'a', 'l'] l
['a', 'l', 'l'] y
['l', 'l', 'y']
['l', 'y', ' '] a
['y', ' ', 'a'] g
[' ', 'a', 'g'] a
['a', 'g', 'a'] i
['g', 'a', 'i'] n
['a', 'i', 'n'] s
['i', 'n', 's'] t
['n', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] a
[' ', 'C', 'a'] i
['C', 'a', 'i'] u
['a', 'i', 'u'] s
['i', 'u', 's']
['u', 's', ' '] M
['s', ' ', 'M'] a
[' ', 'M', 'a'] r
['M', 'a', 'r'] c
['a', 'r', 'c'] i
['r', 'c', 'i'] u
['c', 'i', 'u'] s
['i', 'u', 's'] ?
['u', 's', '?']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['A', 'g', 'a', 'i', 'n', 's', 't', ' ', 'h', 'i', 'm', ' ', 'f', 'i', 'r', 's', 't', ':', ' ', 'h', 'e', "'", 's', ' ', 'a', ' ', 'v', 'e', 'r', 'y', ' ', 'd', 'o', 'g', ' ', 't', 'o', ' ', 't', 'h', 'e', ' ', 'c', 'o', 'm', 'm', 'o', 'n', 'a', 'l', 't', 'y', '.', '\n']
['<pad>', 'A'] g
['<pad>', 'A', 'g'] a
['A', 'g', 'a'] i
['g', 'a', 'i'] n
['a', 'i', 'n'] s
['i', 'n', 's'] t
['n', 's', 't']
['s', 't', ' '] h
['t', ' ', 'h'] i
[' ', 'h', 'i'] m
['h', 'i', 'm']
['i', 'm', ' '] f
['m', ' ', 'f'] i
[' ', 'f', 'i'] r
['f', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't'] :
['s', 't', ':']
['t', ':', ' '] h
[':', ' ', 'h'] e
[' ', 'h', 'e'] '
['h', 'e', "'"] s
['e', "'", 's']
["'", 's', ' '] a
['s', ' ', 'a']
[' ', 'a', ' '] v
['a', ' ', 'v'] e
[' ', 'v', 'e'] r
['v', 'e', 'r'] y
['e', 'r', 'y']
['r', 'y', ' '] d
['y', ' ', 'd'] o
[' ', 'd', 'o'] g
['d', 'o', 'g']
['o', 'g', ' '] t
['g', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] c
['e', ' ', 'c'] o
[' ', 'c', 'o'] m
['c', 'o', 'm'] m
['o', 'm', 'm'] o
['m', 'm', 'o'] n
['m', 'o', 'n'] a
['o', 'n', 'a'] l
['n', 'a', 'l'] t
['a', 'l', 't'] y
['l', 't', 'y'] .
['t', 'y', '.']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['C', 'o', 'n', 's', 'i', 'd', 'e', 'r', ' ', 'y', 'o', 'u', ' ', 'w', 'h', 'a', 't', ' ', 's', 'e', 'r', 'v', 'i', 'c', 'e', 's', ' ', 'h', 'e', ' ', 'h', 'a', 's', ' ', 'd', 'o', 'n', 'e', ' ', 'f', 'o', 'r', ' ', 'h', 'i', 's', ' ', 'c', 'o', 'u', 'n', 't', 'r', 'y', '?', '\n']
['<pad>', 'C'] o
['<pad>', 'C', 'o'] n
['C', 'o', 'n'] s
['o', 'n', 's'] i
['n', 's', 'i'] d
['s', 'i', 'd'] e
['i', 'd', 'e'] r
['d', 'e', 'r']
['e', 'r', ' '] y
['r', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
['o', 'u', ' '] w
['u', ' ', 'w'] h
[' ', 'w', 'h'] a
['w', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] s
['t', ' ', 's'] e
[' ', 's', 'e'] r
['s', 'e', 'r'] v
['e', 'r', 'v'] i
['r', 'v', 'i'] c
['v', 'i', 'c'] e
['i', 'c', 'e'] s
['c', 'e', 's']
['e', 's', ' '] h
['s', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] h
['e', ' ', 'h'] a
[' ', 'h', 'a'] s
['h', 'a', 's']
['a', 's', ' '] d
['s', ' ', 'd'] o
[' ', 'd', 'o'] n
['d', 'o', 'n'] e
['o', 'n', 'e']
['n', 'e', ' '] f
['e', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r']
['o', 'r', ' '] h
['r', ' ', 'h'] i
[' ', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] c
['s', ' ', 'c'] o
[' ', 'c', 'o'] u
['c', 'o', 'u'] n
['o', 'u', 'n'] t
['u', 'n', 't'] r
['n', 't', 'r'] y
['t', 'r', 'y'] ?
['r', 'y', '?']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['V', 'e', 'r', 'y', ' ', 'w', 'e', 'l', 'l', ';', ' ', 'a', 'n', 'd', ' ', 'c', 'o', 'u', 'l', 'd', ' ', 'b', 'e', ' ', 'c', 'o', 'n', 't', 'e', 'n', 't', ' ', 't', 'o', ' ', 'g', 'i', 'v', 'e', ' ', 'h', 'i', 'm', ' ', 'g', 'o', 'o', 'd', '\n']
['<pad>', 'V'] e
['<pad>', 'V', 'e'] r
['V', 'e', 'r'] y
['e', 'r', 'y']
['r', 'y', ' '] w
['y', ' ', 'w'] e
[' ', 'w', 'e'] l
['w', 'e', 'l'] l
['e', 'l', 'l'] ;
['l', 'l', ';']
['l', ';', ' '] a
[';', ' ', 'a'] n
[' ', 'a', 'n'] d
['a', 'n', 'd']
['n', 'd', ' '] c
['d', ' ', 'c'] o
[' ', 'c', 'o'] u
['c', 'o', 'u'] l
['o', 'u', 'l'] d
['u', 'l', 'd']
['l', 'd', ' '] b
['d', ' ', 'b'] e
[' ', 'b', 'e']
['b', 'e', ' '] c
['e', ' ', 'c'] o
[' ', 'c', 'o'] n
['c', 'o', 'n'] t
['o', 'n', 't'] e
['n', 't', 'e'] n
['t', 'e', 'n'] t
['e', 'n', 't']
['n', 't', ' '] t
['t', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] g
['o', ' ', 'g'] i
[' ', 'g', 'i'] v
['g', 'i', 'v'] e
['i', 'v', 'e']
['v', 'e', ' '] h
['e', ' ', 'h'] i
[' ', 'h', 'i'] m
['h', 'i', 'm']
['i', 'm', ' '] g
['m', ' ', 'g'] o
[' ', 'g', 'o'] o
['g', 'o', 'o'] d
['o', 'o', 'd']
row: ['r', 'e', 'p', 'o', 'r', 't', ' ', 'f', 'o', 'r', 't', ',', ' ', 'b', 'u', 't', ' ', 't', 'h', 'a', 't', ' ', 'h', 'e', ' ', 'p', 'a', 'y', 's', ' ', 'h', 'i', 'm', 's', 'e', 'l', 'f', ' ', 'w', 'i', 't', 'h', ' ', 'b', 'e', 'i', 'n', 'g', ' ', 'p', 'r', 'o', 'u', 'd', '.', '\n']
['<pad>', 'r'] e
['<pad>', 'r', 'e'] p
['r', 'e', 'p'] o
['e', 'p', 'o'] r
['p', 'o', 'r'] t
['o', 'r', 't']
['r', 't', ' '] f
['t', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r'] t
['o', 'r', 't'] ,
['r', 't', ',']
['t', ',', ' '] b
[',', ' ', 'b'] u
[' ', 'b', 'u'] t
['b', 'u', 't']
['u', 't', ' '] t
['t', ' ', 't'] h
[' ', 't', 'h'] a
['t', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] h
['t', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] p
['e', ' ', 'p'] a
[' ', 'p', 'a'] y
['p', 'a', 'y'] s
['a', 'y', 's']
['y', 's', ' '] h
['s', ' ', 'h'] i
[' ', 'h', 'i'] m
['h', 'i', 'm'] s
['i', 'm', 's'] e
['m', 's', 'e'] l
['s', 'e', 'l'] f
['e', 'l', 'f']
['l', 'f', ' '] w
['f', ' ', 'w'] i
[' ', 'w', 'i'] t
['w', 'i', 't'] h
['i', 't', 'h']
['t', 'h', ' '] b
['h', ' ', 'b'] e
[' ', 'b', 'e'] i
['b', 'e', 'i'] n
['e', 'i', 'n'] g
['i', 'n', 'g']
['n', 'g', ' '] p
['g', ' ', 'p'] r
[' ', 'p', 'r'] o
['p', 'r', 'o'] u
['r', 'o', 'u'] d
['o', 'u', 'd'] .
['u', 'd', '.']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['N', 'a', 'y', ',', ' ', 'b', 'u', 't', ' ', 's', 'p', 'e', 'a', 'k', ' ', 'n', 'o', 't', ' ', 'm', 'a', 'l', 'i', 'c', 'i', 'o', 'u', 's', 'l', 'y', '.', '\n']
['<pad>', 'N'] a
['<pad>', 'N', 'a'] y
['N', 'a', 'y'] ,
['a', 'y', ',']
['y', ',', ' '] b
[',', ' ', 'b'] u
[' ', 'b', 'u'] t
['b', 'u', 't']
['u', 't', ' '] s
['t', ' ', 's'] p
[' ', 's', 'p'] e
['s', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k']
['a', 'k', ' '] n
['k', ' ', 'n'] o
[' ', 'n', 'o'] t
['n', 'o', 't']
['o', 't', ' '] m
['t', ' ', 'm'] a
[' ', 'm', 'a'] l
['m', 'a', 'l'] i
['a', 'l', 'i'] c
['l', 'i', 'c'] i
['i', 'c', 'i'] o
['c', 'i', 'o'] u
['i', 'o', 'u'] s
['o', 'u', 's'] l
['u', 's', 'l'] y
['s', 'l', 'y'] .
['l', 'y', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['I', ' ', 's', 'a', 'y', ' ', 'u', 'n', 't', 'o', ' ', 'y', 'o', 'u', ',', ' ', 'w', 'h', 'a', 't', ' ', 'h', 'e', ' ', 'h', 'a', 't', 'h', ' ', 'd', 'o', 'n', 'e', ' ', 'f', 'a', 'm', 'o', 'u', 's', 'l', 'y', ',', ' ', 'h', 'e', ' ', 'd', 'i', 'd', '\n']
['<pad>', 'I']
['<pad>', 'I', ' '] s
['I', ' ', 's'] a
[' ', 's', 'a'] y
['s', 'a', 'y']
['a', 'y', ' '] u
['y', ' ', 'u'] n
[' ', 'u', 'n'] t
['u', 'n', 't'] o
['n', 't', 'o']
['t', 'o', ' '] y
['o', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u'] ,
['o', 'u', ',']
['u', ',', ' '] w
[',', ' ', 'w'] h
[' ', 'w', 'h'] a
['w', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] h
['t', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] h
['e', ' ', 'h'] a
[' ', 'h', 'a'] t
['h', 'a', 't'] h
['a', 't', 'h']
['t', 'h', ' '] d
['h', ' ', 'd'] o
[' ', 'd', 'o'] n
['d', 'o', 'n'] e
['o', 'n', 'e']
['n', 'e', ' '] f
['e', ' ', 'f'] a
[' ', 'f', 'a'] m
['f', 'a', 'm'] o
['a', 'm', 'o'] u
['m', 'o', 'u'] s
['o', 'u', 's'] l
['u', 's', 'l'] y
['s', 'l', 'y'] ,
['l', 'y', ',']
['y', ',', ' '] h
[',', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] d
['e', ' ', 'd'] i
[' ', 'd', 'i'] d
['d', 'i', 'd']
row: ['i', 't', ' ', 't', 'o', ' ', 't', 'h', 'a', 't', ' ', 'e', 'n', 'd', ':', ' ', 't', 'h', 'o', 'u', 'g', 'h', ' ', 's', 'o', 'f', 't', '-', 'c', 'o', 'n', 's', 'c', 'i', 'e', 'n', 'c', 'e', 'd', ' ', 'm', 'e', 'n', ' ', 'c', 'a', 'n', ' ', 'b', 'e', '\n']
['<pad>', 'i'] t
['<pad>', 'i', 't']
['i', 't', ' '] t
['t', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] a
['t', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] e
['t', ' ', 'e'] n
[' ', 'e', 'n'] d
['e', 'n', 'd'] :
['n', 'd', ':']
['d', ':', ' '] t
[':', ' ', 't'] h
[' ', 't', 'h'] o
['t', 'h', 'o'] u
['h', 'o', 'u'] g
['o', 'u', 'g'] h
['u', 'g', 'h']
['g', 'h', ' '] s
['h', ' ', 's'] o
[' ', 's', 'o'] f
['s', 'o', 'f'] t
['o', 'f', 't'] -
['f', 't', '-'] c
['t', '-', 'c'] o
['-', 'c', 'o'] n
['c', 'o', 'n'] s
['o', 'n', 's'] c
['n', 's', 'c'] i
['s', 'c', 'i'] e
['c', 'i', 'e'] n
['i', 'e', 'n'] c
['e', 'n', 'c'] e
['n', 'c', 'e'] d
['c', 'e', 'd']
['e', 'd', ' '] m
['d', ' ', 'm'] e
[' ', 'm', 'e'] n
['m', 'e', 'n']
['e', 'n', ' '] c
['n', ' ', 'c'] a
[' ', 'c', 'a'] n
['c', 'a', 'n']
['a', 'n', ' '] b
['n', ' ', 'b'] e
[' ', 'b', 'e']
row: ['c', 'o', 'n', 't', 'e', 'n', 't', ' ', 't', 'o', ' ', 's', 'a', 'y', ' ', 'i', 't', ' ', 'w', 'a', 's', ' ', 'f', 'o', 'r', ' ', 'h', 'i', 's', ' ', 'c', 'o', 'u', 'n', 't', 'r', 'y', ' ', 'h', 'e', ' ', 'd', 'i', 'd', ' ', 'i', 't', ' ', 't', 'o', '\n']
['<pad>', 'c'] o
['<pad>', 'c', 'o'] n
['c', 'o', 'n'] t
['o', 'n', 't'] e
['n', 't', 'e'] n
['t', 'e', 'n'] t
['e', 'n', 't']
['n', 't', ' '] t
['t', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] s
['o', ' ', 's'] a
[' ', 's', 'a'] y
['s', 'a', 'y']
['a', 'y', ' '] i
['y', ' ', 'i'] t
[' ', 'i', 't']
['i', 't', ' '] w
['t', ' ', 'w'] a
[' ', 'w', 'a'] s
['w', 'a', 's']
['a', 's', ' '] f
['s', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r']
['o', 'r', ' '] h
['r', ' ', 'h'] i
[' ', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] c
['s', ' ', 'c'] o
[' ', 'c', 'o'] u
['c', 'o', 'u'] n
['o', 'u', 'n'] t
['u', 'n', 't'] r
['n', 't', 'r'] y
['t', 'r', 'y']
['r', 'y', ' '] h
['y', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] d
['e', ' ', 'd'] i
[' ', 'd', 'i'] d
['d', 'i', 'd']
['i', 'd', ' '] i
['d', ' ', 'i'] t
[' ', 'i', 't']
['i', 't', ' '] t
['t', ' ', 't'] o
[' ', 't', 'o']
row: ['p', 'l', 'e', 'a', 's', 'e', ' ', 'h', 'i', 's', ' ', 'm', 'o', 't', 'h', 'e', 'r', ' ', 'a', 'n', 'd', ' ', 't', 'o', ' ', 'b', 'e', ' ', 'p', 'a', 'r', 't', 'l', 'y', ' ', 'p', 'r', 'o', 'u', 'd', ';', ' ', 'w', 'h', 'i', 'c', 'h', ' ', 'h', 'e', '\n']
['<pad>', 'p'] l
['<pad>', 'p', 'l'] e
['p', 'l', 'e'] a
['l', 'e', 'a'] s
['e', 'a', 's'] e
['a', 's', 'e']
['s', 'e', ' '] h
['e', ' ', 'h'] i
[' ', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] m
['s', ' ', 'm'] o
[' ', 'm', 'o'] t
['m', 'o', 't'] h
['o', 't', 'h'] e
['t', 'h', 'e'] r
['h', 'e', 'r']
['e', 'r', ' '] a
['r', ' ', 'a'] n
[' ', 'a', 'n'] d
['a', 'n', 'd']
['n', 'd', ' '] t
['d', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] b
['o', ' ', 'b'] e
[' ', 'b', 'e']
['b', 'e', ' '] p
['e', ' ', 'p'] a
[' ', 'p', 'a'] r
['p', 'a', 'r'] t
['a', 'r', 't'] l
['r', 't', 'l'] y
['t', 'l', 'y']
['l', 'y', ' '] p
['y', ' ', 'p'] r
[' ', 'p', 'r'] o
['p', 'r', 'o'] u
['r', 'o', 'u'] d
['o', 'u', 'd'] ;
['u', 'd', ';']
['d', ';', ' '] w
[';', ' ', 'w'] h
[' ', 'w', 'h'] i
['w', 'h', 'i'] c
['h', 'i', 'c'] h
['i', 'c', 'h']
['c', 'h', ' '] h
['h', ' ', 'h'] e
[' ', 'h', 'e']
row: ['i', 's', ',', ' ', 'e', 'v', 'e', 'n', ' ', 't', 'i', 'l', 'l', ' ', 't', 'h', 'e', ' ', 'a', 'l', 't', 'i', 't', 'u', 'd', 'e', ' ', 'o', 'f', ' ', 'h', 'i', 's', ' ', 'v', 'i', 'r', 't', 'u', 'e', '.', '\n']
['<pad>', 'i'] s
['<pad>', 'i', 's'] ,
['i', 's', ',']
['s', ',', ' '] e
[',', ' ', 'e'] v
[' ', 'e', 'v'] e
['e', 'v', 'e'] n
['v', 'e', 'n']
['e', 'n', ' '] t
['n', ' ', 't'] i
[' ', 't', 'i'] l
['t', 'i', 'l'] l
['i', 'l', 'l']
['l', 'l', ' '] t
['l', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] a
['e', ' ', 'a'] l
[' ', 'a', 'l'] t
['a', 'l', 't'] i
['l', 't', 'i'] t
['t', 'i', 't'] u
['i', 't', 'u'] d
['t', 'u', 'd'] e
['u', 'd', 'e']
['d', 'e', ' '] o
['e', ' ', 'o'] f
[' ', 'o', 'f']
['o', 'f', ' '] h
['f', ' ', 'h'] i
[' ', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] v
['s', ' ', 'v'] i
[' ', 'v', 'i'] r
['v', 'i', 'r'] t
['i', 'r', 't'] u
['r', 't', 'u'] e
['t', 'u', 'e'] .
['u', 'e', '.']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['W', 'h', 'a', 't', ' ', 'h', 'e', ' ', 'c', 'a', 'n', 'n', 'o', 't', ' ', 'h', 'e', 'l', 'p', ' ', 'i', 'n', ' ', 'h', 'i', 's', ' ', 'n', 'a', 't', 'u', 'r', 'e', ',', ' ', 'y', 'o', 'u', ' ', 'a', 'c', 'c', 'o', 'u', 'n', 't', ' ', 'a', '\n']
['<pad>', 'W'] h
['<pad>', 'W', 'h'] a
['W', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] h
['t', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] c
['e', ' ', 'c'] a
[' ', 'c', 'a'] n
['c', 'a', 'n'] n
['a', 'n', 'n'] o
['n', 'n', 'o'] t
['n', 'o', 't']
['o', 't', ' '] h
['t', ' ', 'h'] e
[' ', 'h', 'e'] l
['h', 'e', 'l'] p
['e', 'l', 'p']
['l', 'p', ' '] i
['p', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] h
['n', ' ', 'h'] i
[' ', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] n
['s', ' ', 'n'] a
[' ', 'n', 'a'] t
['n', 'a', 't'] u
['a', 't', 'u'] r
['t', 'u', 'r'] e
['u', 'r', 'e'] ,
['r', 'e', ',']
['e', ',', ' '] y
[',', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
['o', 'u', ' '] a
['u', ' ', 'a'] c
[' ', 'a', 'c'] c
['a', 'c', 'c'] o
['c', 'c', 'o'] u
['c', 'o', 'u'] n
['o', 'u', 'n'] t
['u', 'n', 't']
['n', 't', ' '] a
['t', ' ', 'a']
row: ['v', 'i', 'c', 'e', ' ', 'i', 'n', ' ', 'h', 'i', 'm', '.', ' ', 'Y', 'o', 'u', ' ', 'm', 'u', 's', 't', ' ', 'i', 'n', ' ', 'n', 'o', ' ', 'w', 'a', 'y', ' ', 's', 'a', 'y', ' ', 'h', 'e', ' ', 'i', 's', ' ', 'c', 'o', 'v', 'e', 't', 'o', 'u', 's', '.', '\n']
['<pad>', 'v'] i
['<pad>', 'v', 'i'] c
['v', 'i', 'c'] e
['i', 'c', 'e']
['c', 'e', ' '] i
['e', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] h
['n', ' ', 'h'] i
[' ', 'h', 'i'] m
['h', 'i', 'm'] .
['i', 'm', '.']
['m', '.', ' '] Y
['.', ' ', 'Y'] o
[' ', 'Y', 'o'] u
['Y', 'o', 'u']
['o', 'u', ' '] m
['u', ' ', 'm'] u
[' ', 'm', 'u'] s
['m', 'u', 's'] t
['u', 's', 't']
['s', 't', ' '] i
['t', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] n
['n', ' ', 'n'] o
[' ', 'n', 'o']
['n', 'o', ' '] w
['o', ' ', 'w'] a
[' ', 'w', 'a'] y
['w', 'a', 'y']
['a', 'y', ' '] s
['y', ' ', 's'] a
[' ', 's', 'a'] y
['s', 'a', 'y']
['a', 'y', ' '] h
['y', ' ', 'h'] e
[' ', 'h', 'e']
['h', 'e', ' '] i
['e', ' ', 'i'] s
[' ', 'i', 's']
['i', 's', ' '] c
['s', ' ', 'c'] o
[' ', 'c', 'o'] v
['c', 'o', 'v'] e
['o', 'v', 'e'] t
['v', 'e', 't'] o
['e', 't', 'o'] u
['t', 'o', 'u'] s
['o', 'u', 's'] .
['u', 's', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['I', 'f', ' ', 'I', ' ', 'm', 'u', 's', 't', ' ', 'n', 'o', 't', ',', ' ', 'I', ' ', 'n', 'e', 'e', 'd', ' ', 'n', 'o', 't', ' ', 'b', 'e', ' ', 'b', 'a', 'r', 'r', 'e', 'n', ' ', 'o', 'f', ' ', 'a', 'c', 'c', 'u', 's', 'a', 't', 'i', 'o', 'n', 's', ';', '\n']
['<pad>', 'I'] f
['<pad>', 'I', 'f']
['I', 'f', ' '] I
['f', ' ', 'I']
[' ', 'I', ' '] m
['I', ' ', 'm'] u
[' ', 'm', 'u'] s
['m', 'u', 's'] t
['u', 's', 't']
['s', 't', ' '] n
['t', ' ', 'n'] o
[' ', 'n', 'o'] t
['n', 'o', 't'] ,
['o', 't', ',']
['t', ',', ' '] I
[',', ' ', 'I']
[' ', 'I', ' '] n
['I', ' ', 'n'] e
[' ', 'n', 'e'] e
['n', 'e', 'e'] d
['e', 'e', 'd']
['e', 'd', ' '] n
['d', ' ', 'n'] o
[' ', 'n', 'o'] t
['n', 'o', 't']
['o', 't', ' '] b
['t', ' ', 'b'] e
[' ', 'b', 'e']
['b', 'e', ' '] b
['e', ' ', 'b'] a
[' ', 'b', 'a'] r
['b', 'a', 'r'] r
['a', 'r', 'r'] e
['r', 'r', 'e'] n
['r', 'e', 'n']
['e', 'n', ' '] o
['n', ' ', 'o'] f
[' ', 'o', 'f']
['o', 'f', ' '] a
['f', ' ', 'a'] c
[' ', 'a', 'c'] c
['a', 'c', 'c'] u
['c', 'c', 'u'] s
['c', 'u', 's'] a
['u', 's', 'a'] t
['s', 'a', 't'] i
['a', 't', 'i'] o
['t', 'i', 'o'] n
['i', 'o', 'n'] s
['o', 'n', 's'] ;
['n', 's', ';']
row: ['h', 'e', ' ', 'h', 'a', 't', 'h', ' ', 'f', 'a', 'u', 'l', 't', 's', ',', ' ', 'w', 'i', 't', 'h', ' ', 's', 'u', 'r', 'p', 'l', 'u', 's', ',', ' ', 't', 'o', ' ', 't', 'i', 'r', 'e', ' ', 'i', 'n', ' ', 'r', 'e', 'p', 'e', 't', 'i', 't', 'i', 'o', 'n', '.', '\n']
['<pad>', 'h'] e
['<pad>', 'h', 'e']
['h', 'e', ' '] h
['e', ' ', 'h'] a
[' ', 'h', 'a'] t
['h', 'a', 't'] h
['a', 't', 'h']
['t', 'h', ' '] f
['h', ' ', 'f'] a
[' ', 'f', 'a'] u
['f', 'a', 'u'] l
['a', 'u', 'l'] t
['u', 'l', 't'] s
['l', 't', 's'] ,
['t', 's', ',']
['s', ',', ' '] w
[',', ' ', 'w'] i
[' ', 'w', 'i'] t
['w', 'i', 't'] h
['i', 't', 'h']
['t', 'h', ' '] s
['h', ' ', 's'] u
[' ', 's', 'u'] r
['s', 'u', 'r'] p
['u', 'r', 'p'] l
['r', 'p', 'l'] u
['p', 'l', 'u'] s
['l', 'u', 's'] ,
['u', 's', ',']
['s', ',', ' '] t
[',', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] i
[' ', 't', 'i'] r
['t', 'i', 'r'] e
['i', 'r', 'e']
['r', 'e', ' '] i
['e', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] r
['n', ' ', 'r'] e
[' ', 'r', 'e'] p
['r', 'e', 'p'] e
['e', 'p', 'e'] t
['p', 'e', 't'] i
['e', 't', 'i'] t
['t', 'i', 't'] i
['i', 't', 'i'] o
['t', 'i', 'o'] n
['i', 'o', 'n'] .
['o', 'n', '.']
row: ['W', 'h', 'a', 't', ' ', 's', 'h', 'o', 'u', 't', 's', ' ', 'a', 'r', 'e', ' ', 't', 'h', 'e', 's', 'e', '?', ' ', 'T', 'h', 'e', ' ', 'o', 't', 'h', 'e', 'r', ' ', 's', 'i', 'd', 'e', ' ', 'o', "'", ' ', 't', 'h', 'e', ' ', 'c', 'i', 't', 'y', '\n']
['<pad>', 'W'] h
['<pad>', 'W', 'h'] a
['W', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] s
['t', ' ', 's'] h
[' ', 's', 'h'] o
['s', 'h', 'o'] u
['h', 'o', 'u'] t
['o', 'u', 't'] s
['u', 't', 's']
['t', 's', ' '] a
['s', ' ', 'a'] r
[' ', 'a', 'r'] e
['a', 'r', 'e']
['r', 'e', ' '] t
['e', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] s
['h', 'e', 's'] e
['e', 's', 'e'] ?
['s', 'e', '?']
['e', '?', ' '] T
['?', ' ', 'T'] h
[' ', 'T', 'h'] e
['T', 'h', 'e']
['h', 'e', ' '] o
['e', ' ', 'o'] t
[' ', 'o', 't'] h
['o', 't', 'h'] e
['t', 'h', 'e'] r
['h', 'e', 'r']
['e', 'r', ' '] s
['r', ' ', 's'] i
[' ', 's', 'i'] d
['s', 'i', 'd'] e
['i', 'd', 'e']
['d', 'e', ' '] o
['e', ' ', 'o'] '
[' ', 'o', "'"]
['o', "'", ' '] t
["'", ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] c
['e', ' ', 'c'] i
[' ', 'c', 'i'] t
['c', 'i', 't'] y
['i', 't', 'y']
row: ['i', 's', ' ', 'r', 'i', 's', 'e', 'n', ':', ' ', 'w', 'h', 'y', ' ', 's', 't', 'a', 'y', ' ', 'w', 'e', ' ', 'p', 'r', 'a', 't', 'i', 'n', 'g', ' ', 'h', 'e', 'r', 'e', '?', ' ', 't', 'o', ' ', 't', 'h', 'e', ' ', 'C', 'a', 'p', 'i', 't', 'o', 'l', '!', '\n']
['<pad>', 'i'] s
['<pad>', 'i', 's']
['i', 's', ' '] r
['s', ' ', 'r'] i
[' ', 'r', 'i'] s
['r', 'i', 's'] e
['i', 's', 'e'] n
['s', 'e', 'n'] :
['e', 'n', ':']
['n', ':', ' '] w
[':', ' ', 'w'] h
[' ', 'w', 'h'] y
['w', 'h', 'y']
['h', 'y', ' '] s
['y', ' ', 's'] t
[' ', 's', 't'] a
['s', 't', 'a'] y
['t', 'a', 'y']
['a', 'y', ' '] w
['y', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] p
['e', ' ', 'p'] r
[' ', 'p', 'r'] a
['p', 'r', 'a'] t
['r', 'a', 't'] i
['a', 't', 'i'] n
['t', 'i', 'n'] g
['i', 'n', 'g']
['n', 'g', ' '] h
['g', ' ', 'h'] e
[' ', 'h', 'e'] r
['h', 'e', 'r'] e
['e', 'r', 'e'] ?
['r', 'e', '?']
['e', '?', ' '] t
['?', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] C
['e', ' ', 'C'] a
[' ', 'C', 'a'] p
['C', 'a', 'p'] i
['a', 'p', 'i'] t
['p', 'i', 't'] o
['i', 't', 'o'] l
['t', 'o', 'l'] !
['o', 'l', '!']
row: ['A', 'l', 'l', ':', '\n']
['<pad>', 'A'] l
['<pad>', 'A', 'l'] l
['A', 'l', 'l'] :
['l', 'l', ':']
row: ['C', 'o', 'm', 'e', ',', ' ', 'c', 'o', 'm', 'e', '.', '\n']
['<pad>', 'C'] o
['<pad>', 'C', 'o'] m
['C', 'o', 'm'] e
['o', 'm', 'e'] ,
['m', 'e', ',']
['e', ',', ' '] c
[',', ' ', 'c'] o
[' ', 'c', 'o'] m
['c', 'o', 'm'] e
['o', 'm', 'e'] .
['m', 'e', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['S', 'o', 'f', 't', '!', ' ', 'w', 'h', 'o', ' ', 'c', 'o', 'm', 'e', 's', ' ', 'h', 'e', 'r', 'e', '?', '\n']
['<pad>', 'S'] o
['<pad>', 'S', 'o'] f
['S', 'o', 'f'] t
['o', 'f', 't'] !
['f', 't', '!']
['t', '!', ' '] w
['!', ' ', 'w'] h
[' ', 'w', 'h'] o
['w', 'h', 'o']
['h', 'o', ' '] c
['o', ' ', 'c'] o
[' ', 'c', 'o'] m
['c', 'o', 'm'] e
['o', 'm', 'e'] s
['m', 'e', 's']
['e', 's', ' '] h
['s', ' ', 'h'] e
[' ', 'h', 'e'] r
['h', 'e', 'r'] e
['e', 'r', 'e'] ?
['r', 'e', '?']
row: ['S', 'e', 'c', 'o', 'n', 'd', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'S'] e
['<pad>', 'S', 'e'] c
['S', 'e', 'c'] o
['e', 'c', 'o'] n
['c', 'o', 'n'] d
['o', 'n', 'd']
['n', 'd', ' '] C
['d', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['W', 'o', 'r', 't', 'h', 'y', ' ', 'M', 'e', 'n', 'e', 'n', 'i', 'u', 's', ' ', 'A', 'g', 'r', 'i', 'p', 'p', 'a', ';', ' ', 'o', 'n', 'e', ' ', 't', 'h', 'a', 't', ' ', 'h', 'a', 't', 'h', ' ', 'a', 'l', 'w', 'a', 'y', 's', ' ', 'l', 'o', 'v', 'e', 'd', '\n']
['<pad>', 'W'] o
['<pad>', 'W', 'o'] r
['W', 'o', 'r'] t
['o', 'r', 't'] h
['r', 't', 'h'] y
['t', 'h', 'y']
['h', 'y', ' '] M
['y', ' ', 'M'] e
[' ', 'M', 'e'] n
['M', 'e', 'n'] e
['e', 'n', 'e'] n
['n', 'e', 'n'] i
['e', 'n', 'i'] u
['n', 'i', 'u'] s
['i', 'u', 's']
['u', 's', ' '] A
['s', ' ', 'A'] g
[' ', 'A', 'g'] r
['A', 'g', 'r'] i
['g', 'r', 'i'] p
['r', 'i', 'p'] p
['i', 'p', 'p'] a
['p', 'p', 'a'] ;
['p', 'a', ';']
['a', ';', ' '] o
[';', ' ', 'o'] n
[' ', 'o', 'n'] e
['o', 'n', 'e']
['n', 'e', ' '] t
['e', ' ', 't'] h
[' ', 't', 'h'] a
['t', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] h
['t', ' ', 'h'] a
[' ', 'h', 'a'] t
['h', 'a', 't'] h
['a', 't', 'h']
['t', 'h', ' '] a
['h', ' ', 'a'] l
[' ', 'a', 'l'] w
['a', 'l', 'w'] a
['l', 'w', 'a'] y
['w', 'a', 'y'] s
['a', 'y', 's']
['y', 's', ' '] l
['s', ' ', 'l'] o
[' ', 'l', 'o'] v
['l', 'o', 'v'] e
['o', 'v', 'e'] d
['v', 'e', 'd']
row: ['t', 'h', 'e', ' ', 'p', 'e', 'o', 'p', 'l', 'e', '.', '\n']
['<pad>', 't'] h
['<pad>', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] p
['e', ' ', 'p'] e
[' ', 'p', 'e'] o
['p', 'e', 'o'] p
['e', 'o', 'p'] l
['o', 'p', 'l'] e
['p', 'l', 'e'] .
['l', 'e', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['H', 'e', "'", 's', ' ', 'o', 'n', 'e', ' ', 'h', 'o', 'n', 'e', 's', 't', ' ', 'e', 'n', 'o', 'u', 'g', 'h', ':', ' ', 'w', 'o', 'u', 'l', 'd', ' ', 'a', 'l', 'l', ' ', 't', 'h', 'e', ' ', 'r', 'e', 's', 't', ' ', 'w', 'e', 'r', 'e', ' ', 's', 'o', '!', '\n']
['<pad>', 'H'] e
['<pad>', 'H', 'e'] '
['H', 'e', "'"] s
['e', "'", 's']
["'", 's', ' '] o
['s', ' ', 'o'] n
[' ', 'o', 'n'] e
['o', 'n', 'e']
['n', 'e', ' '] h
['e', ' ', 'h'] o
[' ', 'h', 'o'] n
['h', 'o', 'n'] e
['o', 'n', 'e'] s
['n', 'e', 's'] t
['e', 's', 't']
['s', 't', ' '] e
['t', ' ', 'e'] n
[' ', 'e', 'n'] o
['e', 'n', 'o'] u
['n', 'o', 'u'] g
['o', 'u', 'g'] h
['u', 'g', 'h'] :
['g', 'h', ':']
['h', ':', ' '] w
[':', ' ', 'w'] o
[' ', 'w', 'o'] u
['w', 'o', 'u'] l
['o', 'u', 'l'] d
['u', 'l', 'd']
['l', 'd', ' '] a
['d', ' ', 'a'] l
[' ', 'a', 'l'] l
['a', 'l', 'l']
['l', 'l', ' '] t
['l', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] r
['e', ' ', 'r'] e
[' ', 'r', 'e'] s
['r', 'e', 's'] t
['e', 's', 't']
['s', 't', ' '] w
['t', ' ', 'w'] e
[' ', 'w', 'e'] r
['w', 'e', 'r'] e
['e', 'r', 'e']
['r', 'e', ' '] s
['e', ' ', 's'] o
[' ', 's', 'o'] !
['s', 'o', '!']
row: ['M', 'E', 'N', 'E', 'N', 'I', 'U', 'S', ':', '\n']
['<pad>', 'M'] E
['<pad>', 'M', 'E'] N
['M', 'E', 'N'] E
['E', 'N', 'E'] N
['N', 'E', 'N'] I
['E', 'N', 'I'] U
['N', 'I', 'U'] S
['I', 'U', 'S'] :
['U', 'S', ':']
row: ['W', 'h', 'a', 't', ' ', 'w', 'o', 'r', 'k', "'", 's', ',', ' ', 'm', 'y', ' ', 'c', 'o', 'u', 'n', 't', 'r', 'y', 'm', 'e', 'n', ',', ' ', 'i', 'n', ' ', 'h', 'a', 'n', 'd', '?', ' ', 'w', 'h', 'e', 'r', 'e', ' ', 'g', 'o', ' ', 'y', 'o', 'u', '\n']
['<pad>', 'W'] h
['<pad>', 'W', 'h'] a
['W', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] w
['t', ' ', 'w'] o
[' ', 'w', 'o'] r
['w', 'o', 'r'] k
['o', 'r', 'k'] '
['r', 'k', "'"] s
['k', "'", 's'] ,
["'", 's', ',']
['s', ',', ' '] m
[',', ' ', 'm'] y
[' ', 'm', 'y']
['m', 'y', ' '] c
['y', ' ', 'c'] o
[' ', 'c', 'o'] u
['c', 'o', 'u'] n
['o', 'u', 'n'] t
['u', 'n', 't'] r
['n', 't', 'r'] y
['t', 'r', 'y'] m
['r', 'y', 'm'] e
['y', 'm', 'e'] n
['m', 'e', 'n'] ,
['e', 'n', ',']
['n', ',', ' '] i
[',', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] h
['n', ' ', 'h'] a
[' ', 'h', 'a'] n
['h', 'a', 'n'] d
['a', 'n', 'd'] ?
['n', 'd', '?']
['d', '?', ' '] w
['?', ' ', 'w'] h
[' ', 'w', 'h'] e
['w', 'h', 'e'] r
['h', 'e', 'r'] e
['e', 'r', 'e']
['r', 'e', ' '] g
['e', ' ', 'g'] o
[' ', 'g', 'o']
['g', 'o', ' '] y
['o', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
row: ['W', 'i', 't', 'h', ' ', 'b', 'a', 't', 's', ' ', 'a', 'n', 'd', ' ', 'c', 'l', 'u', 'b', 's', '?', ' ', 'T', 'h', 'e', ' ', 'm', 'a', 't', 't', 'e', 'r', '?', ' ', 's', 'p', 'e', 'a', 'k', ',', ' ', 'I', ' ', 'p', 'r', 'a', 'y', ' ', 'y', 'o', 'u', '.', '\n']
['<pad>', 'W'] i
['<pad>', 'W', 'i'] t
['W', 'i', 't'] h
['i', 't', 'h']
['t', 'h', ' '] b
['h', ' ', 'b'] a
[' ', 'b', 'a'] t
['b', 'a', 't'] s
['a', 't', 's']
['t', 's', ' '] a
['s', ' ', 'a'] n
[' ', 'a', 'n'] d
['a', 'n', 'd']
['n', 'd', ' '] c
['d', ' ', 'c'] l
[' ', 'c', 'l'] u
['c', 'l', 'u'] b
['l', 'u', 'b'] s
['u', 'b', 's'] ?
['b', 's', '?']
['s', '?', ' '] T
['?', ' ', 'T'] h
[' ', 'T', 'h'] e
['T', 'h', 'e']
['h', 'e', ' '] m
['e', ' ', 'm'] a
[' ', 'm', 'a'] t
['m', 'a', 't'] t
['a', 't', 't'] e
['t', 't', 'e'] r
['t', 'e', 'r'] ?
['e', 'r', '?']
['r', '?', ' '] s
['?', ' ', 's'] p
[' ', 's', 'p'] e
['s', 'p', 'e'] a
['p', 'e', 'a'] k
['e', 'a', 'k'] ,
['a', 'k', ',']
['k', ',', ' '] I
[',', ' ', 'I']
[' ', 'I', ' '] p
['I', ' ', 'p'] r
[' ', 'p', 'r'] a
['p', 'r', 'a'] y
['r', 'a', 'y']
['a', 'y', ' '] y
['y', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u'] .
['o', 'u', '.']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['O', 'u', 'r', ' ', 'b', 'u', 's', 'i', 'n', 'e', 's', 's', ' ', 'i', 's', ' ', 'n', 'o', 't', ' ', 'u', 'n', 'k', 'n', 'o', 'w', 'n', ' ', 't', 'o', ' ', 't', 'h', 'e', ' ', 's', 'e', 'n', 'a', 't', 'e', ';', ' ', 't', 'h', 'e', 'y', ' ', 'h', 'a', 'v', 'e', '\n']
['<pad>', 'O'] u
['<pad>', 'O', 'u'] r
['O', 'u', 'r']
['u', 'r', ' '] b
['r', ' ', 'b'] u
[' ', 'b', 'u'] s
['b', 'u', 's'] i
['u', 's', 'i'] n
['s', 'i', 'n'] e
['i', 'n', 'e'] s
['n', 'e', 's'] s
['e', 's', 's']
['s', 's', ' '] i
['s', ' ', 'i'] s
[' ', 'i', 's']
['i', 's', ' '] n
['s', ' ', 'n'] o
[' ', 'n', 'o'] t
['n', 'o', 't']
['o', 't', ' '] u
['t', ' ', 'u'] n
[' ', 'u', 'n'] k
['u', 'n', 'k'] n
['n', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w'] n
['o', 'w', 'n']
['w', 'n', ' '] t
['n', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] t
['o', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e']
['h', 'e', ' '] s
['e', ' ', 's'] e
[' ', 's', 'e'] n
['s', 'e', 'n'] a
['e', 'n', 'a'] t
['n', 'a', 't'] e
['a', 't', 'e'] ;
['t', 'e', ';']
['e', ';', ' '] t
[';', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] y
['h', 'e', 'y']
['e', 'y', ' '] h
['y', ' ', 'h'] a
[' ', 'h', 'a'] v
['h', 'a', 'v'] e
['a', 'v', 'e']
row: ['h', 'a', 'd', ' ', 'i', 'n', 'k', 'l', 'i', 'n', 'g', ' ', 't', 'h', 'i', 's', ' ', 'f', 'o', 'r', 't', 'n', 'i', 'g', 'h', 't', ' ', 'w', 'h', 'a', 't', ' ', 'w', 'e', ' ', 'i', 'n', 't', 'e', 'n', 'd', ' ', 't', 'o', ' ', 'd', 'o', ',', '\n']
['<pad>', 'h'] a
['<pad>', 'h', 'a'] d
['h', 'a', 'd']
['a', 'd', ' '] i
['d', ' ', 'i'] n
[' ', 'i', 'n'] k
['i', 'n', 'k'] l
['n', 'k', 'l'] i
['k', 'l', 'i'] n
['l', 'i', 'n'] g
['i', 'n', 'g']
['n', 'g', ' '] t
['g', ' ', 't'] h
[' ', 't', 'h'] i
['t', 'h', 'i'] s
['h', 'i', 's']
['i', 's', ' '] f
['s', ' ', 'f'] o
[' ', 'f', 'o'] r
['f', 'o', 'r'] t
['o', 'r', 't'] n
['r', 't', 'n'] i
['t', 'n', 'i'] g
['n', 'i', 'g'] h
['i', 'g', 'h'] t
['g', 'h', 't']
['h', 't', ' '] w
['t', ' ', 'w'] h
[' ', 'w', 'h'] a
['w', 'h', 'a'] t
['h', 'a', 't']
['a', 't', ' '] w
['t', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] i
['e', ' ', 'i'] n
[' ', 'i', 'n'] t
['i', 'n', 't'] e
['n', 't', 'e'] n
['t', 'e', 'n'] d
['e', 'n', 'd']
['n', 'd', ' '] t
['d', ' ', 't'] o
[' ', 't', 'o']
['t', 'o', ' '] d
['o', ' ', 'd'] o
[' ', 'd', 'o'] ,
['d', 'o', ',']
row: ['w', 'h', 'i', 'c', 'h', ' ', 'n', 'o', 'w', ' ', 'w', 'e', "'", 'l', 'l', ' ', 's', 'h', 'o', 'w', ' ', "'", 'e', 'm', ' ', 'i', 'n', ' ', 'd', 'e', 'e', 'd', 's', '.', ' ', 'T', 'h', 'e', 'y', ' ', 's', 'a', 'y', ' ', 'p', 'o', 'o', 'r', '\n']
['<pad>', 'w'] h
['<pad>', 'w', 'h'] i
['w', 'h', 'i'] c
['h', 'i', 'c'] h
['i', 'c', 'h']
['c', 'h', ' '] n
['h', ' ', 'n'] o
[' ', 'n', 'o'] w
['n', 'o', 'w']
['o', 'w', ' '] w
['w', ' ', 'w'] e
[' ', 'w', 'e'] '
['w', 'e', "'"] l
['e', "'", 'l'] l
["'", 'l', 'l']
['l', 'l', ' '] s
['l', ' ', 's'] h
[' ', 's', 'h'] o
['s', 'h', 'o'] w
['h', 'o', 'w']
['o', 'w', ' '] '
['w', ' ', "'"] e
[' ', "'", 'e'] m
["'", 'e', 'm']
['e', 'm', ' '] i
['m', ' ', 'i'] n
[' ', 'i', 'n']
['i', 'n', ' '] d
['n', ' ', 'd'] e
[' ', 'd', 'e'] e
['d', 'e', 'e'] d
['e', 'e', 'd'] s
['e', 'd', 's'] .
['d', 's', '.']
['s', '.', ' '] T
['.', ' ', 'T'] h
[' ', 'T', 'h'] e
['T', 'h', 'e'] y
['h', 'e', 'y']
['e', 'y', ' '] s
['y', ' ', 's'] a
[' ', 's', 'a'] y
['s', 'a', 'y']
['a', 'y', ' '] p
['y', ' ', 'p'] o
[' ', 'p', 'o'] o
['p', 'o', 'o'] r
['o', 'o', 'r']
row: ['s', 'u', 'i', 't', 'o', 'r', 's', ' ', 'h', 'a', 'v', 'e', ' ', 's', 't', 'r', 'o', 'n', 'g', ' ', 'b', 'r', 'e', 'a', 't', 'h', 's', ':', ' ', 't', 'h', 'e', 'y', ' ', 's', 'h', 'a', 'l', 'l', ' ', 'k', 'n', 'o', 'w', ' ', 'w', 'e', '\n']
['<pad>', 's'] u
['<pad>', 's', 'u'] i
['s', 'u', 'i'] t
['u', 'i', 't'] o
['i', 't', 'o'] r
['t', 'o', 'r'] s
['o', 'r', 's']
['r', 's', ' '] h
['s', ' ', 'h'] a
[' ', 'h', 'a'] v
['h', 'a', 'v'] e
['a', 'v', 'e']
['v', 'e', ' '] s
['e', ' ', 's'] t
[' ', 's', 't'] r
['s', 't', 'r'] o
['t', 'r', 'o'] n
['r', 'o', 'n'] g
['o', 'n', 'g']
['n', 'g', ' '] b
['g', ' ', 'b'] r
[' ', 'b', 'r'] e
['b', 'r', 'e'] a
['r', 'e', 'a'] t
['e', 'a', 't'] h
['a', 't', 'h'] s
['t', 'h', 's'] :
['h', 's', ':']
['s', ':', ' '] t
[':', ' ', 't'] h
[' ', 't', 'h'] e
['t', 'h', 'e'] y
['h', 'e', 'y']
['e', 'y', ' '] s
['y', ' ', 's'] h
[' ', 's', 'h'] a
['s', 'h', 'a'] l
['h', 'a', 'l'] l
['a', 'l', 'l']
['l', 'l', ' '] k
['l', ' ', 'k'] n
[' ', 'k', 'n'] o
['k', 'n', 'o'] w
['n', 'o', 'w']
['o', 'w', ' '] w
['w', ' ', 'w'] e
[' ', 'w', 'e']
row: ['h', 'a', 'v', 'e', ' ', 's', 't', 'r', 'o', 'n', 'g', ' ', 'a', 'r', 'm', 's', ' ', 't', 'o', 'o', '.', '\n']
['<pad>', 'h'] a
['<pad>', 'h', 'a'] v
['h', 'a', 'v'] e
['a', 'v', 'e']
['v', 'e', ' '] s
['e', ' ', 's'] t
[' ', 's', 't'] r
['s', 't', 'r'] o
['t', 'r', 'o'] n
['r', 'o', 'n'] g
['o', 'n', 'g']
['n', 'g', ' '] a
['g', ' ', 'a'] r
[' ', 'a', 'r'] m
['a', 'r', 'm'] s
['r', 'm', 's']
['m', 's', ' '] t
['s', ' ', 't'] o
[' ', 't', 'o'] o
['t', 'o', 'o'] .
['o', 'o', '.']
row: ['M', 'E', 'N', 'E', 'N', 'I', 'U', 'S', ':', '\n']
['<pad>', 'M'] E
['<pad>', 'M', 'E'] N
['M', 'E', 'N'] E
['E', 'N', 'E'] N
['N', 'E', 'N'] I
['E', 'N', 'I'] U
['N', 'I', 'U'] S
['I', 'U', 'S'] :
['U', 'S', ':']
row: ['W', 'h', 'y', ',', ' ', 'm', 'a', 's', 't', 'e', 'r', 's', ',', ' ', 'm', 'y', ' ', 'g', 'o', 'o', 'd', ' ', 'f', 'r', 'i', 'e', 'n', 'd', 's', ',', ' ', 'm', 'i', 'n', 'e', ' ', 'h', 'o', 'n', 'e', 's', 't', ' ', 'n', 'e', 'i', 'g', 'h', 'b', 'o', 'u', 'r', 's', ',', '\n']
['<pad>', 'W'] h
['<pad>', 'W', 'h'] y
['W', 'h', 'y'] ,
['h', 'y', ',']
['y', ',', ' '] m
[',', ' ', 'm'] a
[' ', 'm', 'a'] s
['m', 'a', 's'] t
['a', 's', 't'] e
['s', 't', 'e'] r
['t', 'e', 'r'] s
['e', 'r', 's'] ,
['r', 's', ',']
['s', ',', ' '] m
[',', ' ', 'm'] y
[' ', 'm', 'y']
['m', 'y', ' '] g
['y', ' ', 'g'] o
[' ', 'g', 'o'] o
['g', 'o', 'o'] d
['o', 'o', 'd']
['o', 'd', ' '] f
['d', ' ', 'f'] r
[' ', 'f', 'r'] i
['f', 'r', 'i'] e
['r', 'i', 'e'] n
['i', 'e', 'n'] d
['e', 'n', 'd'] s
['n', 'd', 's'] ,
['d', 's', ',']
['s', ',', ' '] m
[',', ' ', 'm'] i
[' ', 'm', 'i'] n
['m', 'i', 'n'] e
['i', 'n', 'e']
['n', 'e', ' '] h
['e', ' ', 'h'] o
[' ', 'h', 'o'] n
['h', 'o', 'n'] e
['o', 'n', 'e'] s
['n', 'e', 's'] t
['e', 's', 't']
['s', 't', ' '] n
['t', ' ', 'n'] e
[' ', 'n', 'e'] i
['n', 'e', 'i'] g
['e', 'i', 'g'] h
['i', 'g', 'h'] b
['g', 'h', 'b'] o
['h', 'b', 'o'] u
['b', 'o', 'u'] r
['o', 'u', 'r'] s
['u', 'r', 's'] ,
['r', 's', ',']
row: ['W', 'i', 'l', 'l', ' ', 'y', 'o', 'u', ' ', 'u', 'n', 'd', 'o', ' ', 'y', 'o', 'u', 'r', 's', 'e', 'l', 'v', 'e', 's', '?', '\n']
['<pad>', 'W'] i
['<pad>', 'W', 'i'] l
['W', 'i', 'l'] l
['i', 'l', 'l']
['l', 'l', ' '] y
['l', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u']
['o', 'u', ' '] u
['u', ' ', 'u'] n
[' ', 'u', 'n'] d
['u', 'n', 'd'] o
['n', 'd', 'o']
['d', 'o', ' '] y
['o', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u'] r
['o', 'u', 'r'] s
['u', 'r', 's'] e
['r', 's', 'e'] l
['s', 'e', 'l'] v
['e', 'l', 'v'] e
['l', 'v', 'e'] s
['v', 'e', 's'] ?
['e', 's', '?']
row: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n']
['<pad>', 'F'] i
['<pad>', 'F', 'i'] r
['F', 'i', 'r'] s
['i', 'r', 's'] t
['r', 's', 't']
['s', 't', ' '] C
['t', ' ', 'C'] i
[' ', 'C', 'i'] t
['C', 'i', 't'] i
['i', 't', 'i'] z
['t', 'i', 'z'] e
['i', 'z', 'e'] n
['z', 'e', 'n'] :
['e', 'n', ':']
row: ['W', 'e', ' ', 'c', 'a', 'n', 'n', 'o', 't', ',', ' ', 's', 'i', 'r', ',', ' ', 'w', 'e', ' ', 'a', 'r', 'e', ' ', 'u', 'n', 'd', 'o', 'n', 'e', ' ', 'a', 'l', 'r', 'e', 'a', 'd', 'y', '.', '\n']
['<pad>', 'W'] e
['<pad>', 'W', 'e']
['W', 'e', ' '] c
['e', ' ', 'c'] a
[' ', 'c', 'a'] n
['c', 'a', 'n'] n
['a', 'n', 'n'] o
['n', 'n', 'o'] t
['n', 'o', 't'] ,
['o', 't', ',']
['t', ',', ' '] s
[',', ' ', 's'] i
[' ', 's', 'i'] r
['s', 'i', 'r'] ,
['i', 'r', ',']
['r', ',', ' '] w
[',', ' ', 'w'] e
[' ', 'w', 'e']
['w', 'e', ' '] a
['e', ' ', 'a'] r
[' ', 'a', 'r'] e
['a', 'r', 'e']
['r', 'e', ' '] u
['e', ' ', 'u'] n
[' ', 'u', 'n'] d
['u', 'n', 'd'] o
['n', 'd', 'o'] n
['d', 'o', 'n'] e
['o', 'n', 'e']
['n', 'e', ' '] a
['e', ' ', 'a'] l
[' ', 'a', 'l'] r
['a', 'l', 'r'] e
['l', 'r', 'e'] a
['r', 'e', 'a'] d
['e', 'a', 'd'] y
['a', 'd', 'y'] .
['d', 'y', '.']
row: ['M', 'E', 'N', 'E', 'N', 'I', 'U', 'S', ':', '\n']
['<pad>', 'M'] E
['<pad>', 'M', 'E'] N
['M', 'E', 'N'] E
['E', 'N', 'E'] N
['N', 'E', 'N'] I
['E', 'N', 'I'] U
['N', 'I', 'U'] S
['I', 'U', 'S'] :
['U', 'S', ':']
row: ['I', ' ', 't', 'e', 'l', 'l', ' ', 'y', 'o', 'u', ',', ' ', 'f', 'r', 'i', 'e', 'n', 'd', 's', ',', ' ', 'm', 'o', 's', 't', ' ', 'c', 'h', 'a', 'r', 'i', 't', 'a', 'b', 'l', 'e', ' ', 'c', 'a', 'r', 'e', '\n']
['<pad>', 'I']
['<pad>', 'I', ' '] t
['I', ' ', 't'] e
[' ', 't', 'e'] l
['t', 'e', 'l'] l
['e', 'l', 'l']
['l', 'l', ' '] y
['l', ' ', 'y'] o
[' ', 'y', 'o'] u
['y', 'o', 'u'] ,
['o', 'u', ',']
['u', ',', ' '] f
[',', ' ', 'f'] r
[' ', 'f', 'r'] i
['f', 'r', 'i'] e
['r', 'i', 'e'] n
['i', 'e', 'n'] d
['e', 'n', 'd'] s
['n', 'd', 's'] ,
['d', 's', ',']
['s', ',', ' '] m
[',', ' ', 'm'] o
[' ', 'm', 'o'] s
['m', 'o', 's'] t
['o', 's', 't']
['s', 't', ' '] c
['t', ' ', 'c'] h
[' ', 'c', 'h'] a
['c', 'h', 'a'] r
['h', 'a', 'r'] i
['a', 'r', 'i'] t
['r', 'i', 't'] a
['i', 't', 'a'] b
['t', 'a', 'b'] l
['a', 'b', 'l'] e
['b', 'l', 'e']
['l', 'e', ' '] c
['e', ' ', 'c'] a
[' ', 'c', 'a'] r
['c', 'a', 'r'] e
['a', 'r', 'e']
X: torch.Size([2623, 3]) y: torch.Size([2623])https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
# F.one_hot(torch.tensor(5), num_classes=n_vocab).float()@C # == C[5]# config model
conf = NNLMConfig(n_vocab=len(v), n_context=CONTEXT_LEN)
lm = NNLM(**asdict(conf))
# test data
bs = 25
x = torch.randint(conf.n_vocab, (bs, conf.n_context)) # (B, T) with values between 0 and n_vocab
print("X (B, T):", x.shape)
# prediction
y = lm(x)
print("Y_hat logits (B, n_vocab):", y.shape)[21:05:27] INFO - NNLM: InitX (B, T): torch.Size([25, 3])
Y_hat logits (B, n_vocab): torch.Size([25, 67])Xtr, Ytr = make_dataset(data[:80], v, context_length=CONTEXT_LEN)
Xdev, Ydev = make_dataset(data[80:90], v)
Xte, Yte = make_dataset(data[90:100], v)
print("Xtr (B, T): ", Xtr.shape, "Ytr (B): ", Ytr.shape, "data:", len(data[:80]))
print("len Xtr: ", len(Xtr))
print("CONTEXT_LEN: ", CONTEXT_LEN)Xtr (B, T): torch.Size([2623, 3]) Ytr (B): torch.Size([2623]) data: 80
len Xtr: 2623
CONTEXT_LEN: 3device = get_device()
device = 'cpu'
# lm.to(device)
# overfit on one big batch
optim = SGD(lm.parameters(), lr=0.01, momentum=0.9)
train_loss = []
ITER_MAX = 1000
for i in tqdm(range(ITER_MAX)):
# for batch in dm.train_dataloader():
# Xtr, Ytr = batch
# Ytr = Ytr[:, -1]
Xtr = Xtr.to(device)
Ytr = Ytr.to(device)
optim.zero_grad()
logits = lm(Xtr)
loss = F.cross_entropy(logits, Ytr)
loss.backward()
optim.step()
train_loss.append(loss.item())
if not(i%250):
print(loss.item())[21:05:27] INFO - Using device: mpsCPU times: user 5 μs, sys: 4 μs, total: 9 μs
Wall time: 2.15 μs 6%|▌ | 59/1000 [00:00<00:01, 588.98it/s]4.189066410064697 38%|███▊ | 376/1000 [00:00<00:01, 611.20it/s]2.6202232837677 62%|██████▏ | 623/1000 [00:01<00:00, 599.64it/s]2.3751416206359863 86%|████████▌ | 860/1000 [00:01<00:00, 535.46it/s]2.199942111968994100%|██████████| 1000/1000 [00:01<00:00, 575.01it/s]plt.plot(train_loss)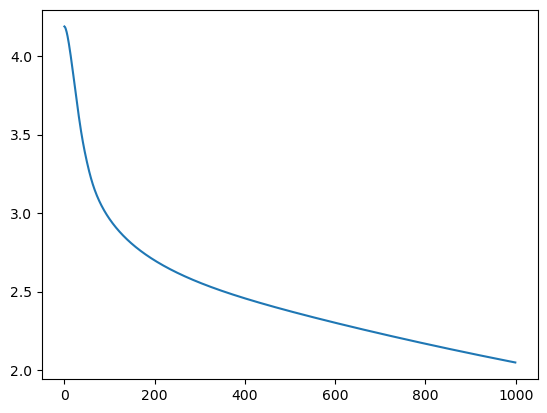
# infer on CPU
lm.to('cpu')
prompt = "The country of "
sequences = lm.sample(prompt, v, max_new_tokens=250, temperature=0.6)
print(sequences)The country of that Citiz he that ss aer he the the hat yire to den fim to the the bu fh thas you ko gour puicen: cat Citizen:
YYde we pa coond Citizes aft iaizet arr you arat we poor pour, bat peo:
peap hith hame her to the fat you apithey hiss bou to the so thecfg = OmegaConf.load("../config/text/data/tinyshakespeare.yaml")
# use <unk> and <pad> to be consistent with manual data preprocessing and have smae vocabulary size
v = Vocab(data_path='../data/text/tiny_shakespeare.txt', specials=['<unk>','<pad>'])
print("vocabulary: ", v.vocabulary)
print("vocabulary size: ", len(v))
print(cfg)
cfg.train_val_test_split = [0.8, 0.1, 0.1]
# by default data_path is relative to the recipe folder so need to update for nbs
cfg.data_path = "../data/text/tiny_shakespeare.txt"
cfg.context_size = CONTEXT_LEN
cfg.batch_size = 2700 # large batch to mimic manual data order of magnitude
cfg.random_split = False
cfg.specials=['<unk>', '<pad>']
cfg.add_sentence_tokens = False
print(cfg)
dm = instantiate(cfg)
dm.setup()
print("vocab size: ", dm.vocab_size)
# setup large batch to overfit / test model
Xtr, Ytr= next(iter(dm.train_dataloader()))
# target is last token in sequence
Ytr = Ytr[:, -1]
print("Xtr (B, T): ", Xtr.shape, "Ytr (B): ", Ytr.shape)
X, Y = dm.train_ds[0]
print(dm.ds.from_tokens(X), dm.ds.from_tokens(Y))[21:05:29] INFO - Vocab: read text file
[21:05:29] INFO - CharDataModule: init
[21:05:29] INFO - CharDataModule: setup, split datasets
[21:05:29] INFO - CharDataset: init
[21:05:29] INFO - Vocab: read text file
[21:05:29] INFO - Split dataset into train/val/test. Keep sequence order.vocabulary: ['\n', ' ', '!', '$', '&', "'", ',', '-', '.', '3', ':', ';', '<pad>', '<unk>', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
vocabulary size: 67
{'_target_': 'nimrod.text.datasets.CharDataModule', 'data_path': '../data/text/tiny_shakespeare.txt', 'specials': ['<pad>', '<unk>'], 'add_sentence_tokens': False, 'train_val_test_split': [0.8, 0.1, 0.1], 'random_split': False, 'batch_size': 64, 'context_size': 3, 'num_workers': 0, 'pin_memory': False, 'persistent_workers': False}
{'_target_': 'nimrod.text.datasets.CharDataModule', 'data_path': '../data/text/tiny_shakespeare.txt', 'specials': ['<unk>', '<pad>'], 'add_sentence_tokens': False, 'train_val_test_split': [0.8, 0.1, 0.1], 'random_split': False, 'batch_size': 2700, 'context_size': 3, 'num_workers': 0, 'pin_memory': False, 'persistent_workers': False}
vocab size: 67
Xtr (B, T): torch.Size([2700, 3]) Ytr (B): torch.Size([2700])
Fir irsconf = NNLMConfig(n_vocab=len(v), n_context=CONTEXT_LEN)
print(len(v), CONTEXT_LEN)
lm = NNLM(**asdict(conf))
bs = 10
x = torch.randint(conf.n_vocab, (bs, conf.n_context)) # (B, T) with values between 0 and n_vocab
print("X (B, T):", x.shape)
lm(x).shape[21:05:29] INFO - NNLM: Init67 3
X (B, T): torch.Size([10, 3])torch.Size([10, 67])# checking data tokens are between 0 and vocab size
print(Xtr.min(), Xtr.max())tensor(0) tensor(66)# device = get_device()
device = 'cpu'
lm.to(device)
# overfit on one big batch
optim = SGD(lm.parameters(), lr=0.01, momentum=0.9)
train_loss = []
ITER_MAX = 1000
for i in tqdm(range(ITER_MAX)):
# for batch in dm.train_dataloader():
# Xtr, Ytr = batch
# Ytr = Ytr[:, -1]
Xtr = Xtr.to(device)
Ytr = Ytr.to(device)
optim.zero_grad()
logits = lm(Xtr)
loss = F.cross_entropy(logits, Ytr)
loss.backward()
optim.step()
train_loss.append(loss.item())
if not(i%250):
print(loss.item())CPU times: user 5 μs, sys: 3 μs, total: 8 μs
Wall time: 14.1 μs 0%| | 0/1000 [00:00<?, ?it/s]4.245690822601318 32%|███▏ | 315/1000 [00:00<00:01, 632.60it/s]2.785951852798462 58%|█████▊ | 584/1000 [00:00<00:00, 658.39it/s]2.5501415729522705 88%|████████▊ | 877/1000 [00:01<00:00, 710.10it/s]2.4038991928100586100%|██████████| 1000/1000 [00:01<00:00, 660.55it/s]plt.plot(train_loss)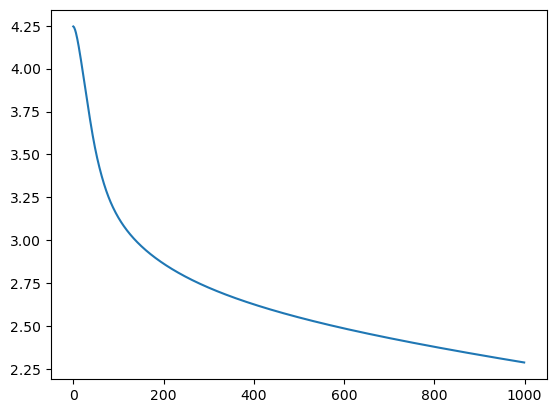
# infer on CPU
lm.to('cpu')
prompt = "The country of "
sequences = lm.sample(prompt, v, max_new_tokens=250, temperature=0.6)
print(sequences)The country of the er thoR mis thath the en sean en od thath
The Itrer lower wy he forat ime they thands siee s and, in thand and sourus is has that R her bovertho for hat wom tuer hand ny deme tharpit us me the ond Iore forr,aty de chee utrer str and ne tore yode
# mini batch gradient descent with datamodule
cfg = OmegaConf.load("../config/text/data/tinyshakespeare.yaml")
cfg.train_val_test_split = [0.8, 0.1, 0.1]
cfg.data_path = "../data/text/tiny_shakespeare.txt"
cfg.context_size = CONTEXT_LEN
cfg.batch_size = 2048
cfg.random_split = False
cfg.specials=['<unk>', '<pad>']
cfg.add_sentence_tokens = False
dm = instantiate(cfg)
dm.setup()
conf = NNLMConfig(n_vocab=len(v), n_context=CONTEXT_LEN)
lm = NNLM(**asdict(conf))[21:05:31] INFO - CharDataModule: init
[21:05:31] INFO - CharDataModule: setup, split datasets
[21:05:31] INFO - CharDataset: init
[21:05:31] INFO - Vocab: read text file
[21:05:31] INFO - Split dataset into train/val/test. Keep sequence order.
[21:05:31] INFO - NNLM: Initoptim = SGD(lm.parameters(), lr=0.01, momentum=0.9)
train_loss = []
# device = get_device()
device = 'cpu'
lm.to(device)
i = 0
EPOCHS = 1
for epoch in tqdm(range(EPOCHS)):
print(f"epoch {epoch}")
for batch in tqdm(dm.train_dataloader()):
Xtr, Ytr = batch
# target is last token in sequence
Ytr = Ytr[:, -1] # BxT
Xtr = Xtr.to(device)
Ytr = Ytr.to(device)
logits = lm(Xtr)
loss = F.cross_entropy(logits, Ytr)
optim.zero_grad()
loss.backward()
optim.step()
train_loss.append(loss.item())
if not(i%1000):
print(loss.item())
i += 1CPU times: user 1e+03 ns, sys: 0 ns, total: 1e+03 ns
Wall time: 2.86 μs 0%| | 0/1 [00:00<?, ?it/s]epoch 04.255069255828857100%|██████████| 436/436 [00:04<00:00, 102.77it/s]
100%|██████████| 1/1 [00:04<00:00, 4.24s/it]plt.plot(train_loss)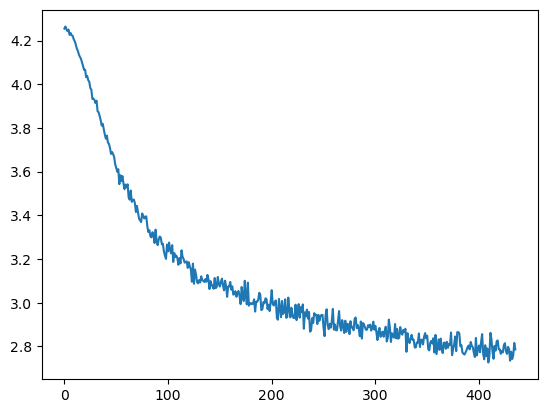
# infer on CPU
lm.to('cpu')
prompt = "The country of "
sequences = lm.sample(prompt, v, max_new_tokens=500, temperature=0.9)
print(sequences)The country of taana, barN.g! eat th re dae b, lod tend his anc tolize
arod ong
C FB Sind frmae g,alfre y m-vxfYout lo w
Xht mn is woEhas foroofd ty uhismam the touw ier, wlins erud ig, nougs hit nn worle ay pnrgells hy
&$, hut sh lis mis unnd
uolem
y the .erersDmater,seylr.
Anns topgovbso nrt oh totlm :umd hadxhe u wow:he bA sep i; lo raa
wouor se th Uho!llpdd?Qugot tousus sa f hI stheris
oll y,
a nn ooltcey cany hQm,vf aurswoua ar, aolnvend hey storg oS ;ins ken oob'chit nf hasoufy brOir. momJ thithe# omegaconf
cfg = OmegaConf.load("../config/text/model/nnlm.yaml")
cfg.num_classes = len(v)
print(len(v))
# have to convert omegaconf dict to dict for pprint
opt = instantiate(cfg.optimizer)
print(opt.keywords['lr'])
pprint.pprint(dict(cfg))
lm = instantiate(cfg)
print(lm.hparams.optimizer)[21:06:10] INFO - NNLM: Init
[21:06:10] INFO - NNLM_X: Init67
0.001
{'_target_': 'nimrod.models.lm.NNLM_X',
'nnet': {'_target_': 'nimrod.models.lm.NNLM', 'n_vocab': '${num_classes}', 'n_emb': 10, 'n_context': 3, 'n_h': 100},
'num_classes': 67,
'optimizer': {'_target_': 'torch.optim.Adam', '_partial_': True, 'lr': 0.001, 'weight_decay': 1e-05},
'scheduler': {'_target_': 'torch.optim.lr_scheduler.ReduceLROnPlateau', '_partial_': True, 'mode': 'min', 'factor': 0.1, 'patience': 10}}--------------------------------------------------------------------------- TypeError Traceback (most recent call last) File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/hydra/_internal/instantiate/_instantiate2.py:92, in _call_target(_target_, _partial_, args, kwargs, full_key) 91 try: ---> 92 return _target_(*args, **kwargs) 93 except Exception as e: File ~/Projects/nimrod/nimrod/models/lm.py:99, in NNLM_X.__init__(self, nnet, num_classes, optimizer, scheduler) 98 logger.info("NNLM_X: Init") ---> 99 super().__init__( 100 num_classes, 101 optimizer, 102 scheduler, 103 ) 104 self.save_hyperparameters(logger=False) TypeError: Classifier.__init__() missing 1 required positional argument: 'scheduler' The above exception was the direct cause of the following exception: InstantiationException Traceback (most recent call last) Cell In[30], line 10 7 print(opt.keywords['lr']) 9 pprint.pprint(dict(cfg)) ---> 10 lm = instantiate(cfg) 11 print(lm.hparams.optimizer) File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/hydra/_internal/instantiate/_instantiate2.py:226, in instantiate(config, *args, **kwargs) 223 _convert_ = config.pop(_Keys.CONVERT, ConvertMode.NONE) 224 _partial_ = config.pop(_Keys.PARTIAL, False) --> 226 return instantiate_node( 227 config, *args, recursive=_recursive_, convert=_convert_, partial=_partial_ 228 ) 229 elif OmegaConf.is_list(config): 230 # Finalize config (convert targets to strings, merge with kwargs) 231 config_copy = copy.deepcopy(config) File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/hydra/_internal/instantiate/_instantiate2.py:347, in instantiate_node(node, convert, recursive, partial, *args) 342 value = instantiate_node( 343 value, convert=convert, recursive=recursive 344 ) 345 kwargs[key] = _convert_node(value, convert) --> 347 return _call_target(_target_, partial, args, kwargs, full_key) 348 else: 349 # If ALL or PARTIAL non structured or OBJECT non structured, 350 # instantiate in dict and resolve interpolations eagerly. 351 if convert == ConvertMode.ALL or ( 352 convert in (ConvertMode.PARTIAL, ConvertMode.OBJECT) 353 and node._metadata.object_type in (None, dict) 354 ): File ~/miniforge3/envs/nimrod/lib/python3.11/site-packages/hydra/_internal/instantiate/_instantiate2.py:97, in _call_target(_target_, _partial_, args, kwargs, full_key) 95 if full_key: 96 msg += f"\nfull_key: {full_key}" ---> 97 raise InstantiationException(msg) from e InstantiationException: Error in call to target 'nimrod.models.lm.NNLM_X': TypeError("Classifier.__init__() missing 1 required positional argument: 'scheduler'")
n_samples = 25
x = torch.randint(conf.n_vocab, (n_samples, cfg.nnet.n_context))
print("X:", x.shape)y = lm(x)
print("Y_hat logits:", y.shape)
# perplexity sanity check: a uniform distribution over V classes has perplexity == V
from nimrod.models.lm import perplexity
_V = 50
_ppl = perplexity(torch.zeros(8, _V), torch.randint(0, _V, (8,)))
assert torch.isclose(_ppl, torch.tensor(float(_V)), atol=1e-4), _ppl
print("perplexity(uniform, V=50) =", _ppl.item())# v = Vocab(data_path='../data/text/tiny_shakespeare.txt', specials=['<unk>','<pad>'])
lm.sample("The country of ", v, max_new_tokens=500, temperature=0.9)# vocab
print(len(v))
# data
cfg = OmegaConf.load("../config/text/data/tinyshakespeare.yaml")
cfg.context_size = CONTEXT_LEN
cfg.specials: ["<pad>", "<unk>"]
cfg.batch_size = 2048
cfg.random_split = False
dm = instantiate(cfg)
dm.setup()
# model
cfg = OmegaConf.load("../config/text/model/nnlm.yaml")
lm = instantiate(cfg)print(lm.__dict__)model can be easily trained with L trainer (c.f. recipes/text/ for examples)
trainer = Trainer(
accelerator="auto",
max_epochs=1,
logger=CSVLogger("logs", name="nnlm")
)trainer.fit(lm, dm.train_dataloader(), dm.val_dataloader())csv_path = f"{trainer.logger.log_dir}/metrics.csv"
metrics = pd.read_csv(csv_path)
metrics.head()plt.plot(metrics['step'], metrics['train/loss_step'],'b.-')
plt.plot(metrics['step'], metrics['val/loss'],'r.-')
plt.show()trainer.test(lm, dm.test_dataloader())# infer on CPU
lm.to('cpu')
prompt = "The country of "
sequences = lm.sample(prompt, v, max_new_tokens=500, temperature=0.9)
print(sequences)lm.hparamstrainer = L.Trainer(
accelerator="auto",
max_epochs=1,
)
tuner = Tuner(trainer)
lr_finder = tuner.lr_find(
lm,
datamodule=dm,
min_lr=1e-6,
max_lr=1.0,
num_training=100, # number of iterations
# attr_name="optimizer.lr",
)
fig = lr_finder.plot(suggest=True)
plt.show()
print(f"Suggested learning rate: {lr_finder.suggestion()}")new_lr = lr_finder.suggestion()
lm.lr = new_lrtrainer = L.Trainer(
accelerator="auto",
max_epochs=1,
logger=CSVLogger("logs", name="nnlm"),
)
trainer.fit(lm, dm.train_dataloader(), dm.val_dataloader())
trainer.test(lm, dm.test_dataloader())csv_path = f"{trainer.logger.log_dir}/metrics.csv"
metrics = pd.read_csv(csv_path)
plt.plot(metrics['step'], metrics['train/loss_step'],'.-')
# plt.figure()
# plot_classifier_metrics_from_csv(csv_path)# infer on CPU
lm.to('cpu')
prompt = "The country of "
sequences = lm.sample(prompt, v, max_new_tokens=500, temperature=0.9)
print(sequences)B, T, C = 32, 8, 65
vocab_size = C
model = NNBigram(vocab_size)
print("vocab size: ", model.vocab_size)
X = torch.randint(0,C,(B,T))
Y = torch.randint(0,C,(B,T))
batch = (X,Y)
logits = model(X) # (B, T, C)
print("X: ", X.shape, "Y: ", Y.shape, "logits: ", logits.shape)# generate
model.predict(idx=torch.zeros((1,1), dtype=torch.long), max_new_tokens=100)[0]# #| export
# class NNBigramL(ModelModule):
# def __init__(self, vocab_size:int, lr:float=1e-3):
# model = NNBigram(vocab_size)
# super().__init__(model, lr)
# self.accuracy = Accuracy(task='multiclass', num_classes=model.vocab_size)
# def _step(self, batch:torch.tensor, batch_idx:int):
# x, y = batch
# logits = self.model(x) # (B,T,C)
# B, T, C = logits.shape
# logits = logits.view(B*T, C)
# y = y.view(B*T)
# loss = self.loss(logits, y)
# acc = self.accuracy(logits, y)
# return loss, acc
# def predict(self,idx:torch.IntTensor, max_new_tokens:int):
# return self.model.predict(idx, max_new_tokens)# model_pl = NNBigramL(vocab_size)
# logits = model_pl(X) # (B, T, C)
# print(logits.shape)
# model_pl.training_step(batch, 0)
# model_pl._step(batch, 0)with open('../data/text/tiny_shakespeare.txt') as f:
text = f.read()# dataset
block_size = 8
ds = CharDataset(data_path='../data/text/tiny_shakespeare.txt', context_length=block_size)
X,Y = ds[0]
print("x:", ds.from_tokens(X), "\ny:", ds.from_tokens(Y))# dataloader
dl = DataLoader(ds, batch_size=32, num_workers=0)
X, Y = next(iter(dl))
print("x:", X.shape, "\ny:", Y.shape)model = NNBigram(ds.vocab_size)criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
device = torch.device('cpu')ITER_MAX = 1000
train_loss = []
for epoch in tqdm(range(ITER_MAX)):
model.train()
X = X.to(device) # (B,T)
Y = Y.to(device) # (B,T)
logits = model(X)
B, T, C = logits.shape
loss = criterion(logits.view(B*T, C), Y.view(B*T))
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if not(epoch % 1000):
print(loss.item())
model.eval()
with torch.no_grad():
correct = 0
total = 0
logits = model(X).view(B*T,C)
# _, predicted = torch.max(logits.data, 1)
probs = F.softmax(logits, dim=-1)
# print("probs: ", probs.shape)
preds = torch.argmax(probs, dim=1)
# print("pred:", preds.shape)
# print("Y:", Y.shape)
# print(predicted)
# total += Y.size(0)
# correct += (predicted == Y).sum()
# print(f"Epoch {epoch + 1}: Accuracy = {100 * correct / total:.2f}%")plt.plot(train_loss)print(ds.from_tokens(model.predict(idx=torch.zeros((1,1), dtype=torch.long), max_new_tokens=500)[0].tolist()))# %%time
# n_epochs = 1
# train_loss = []
# for epoch in range(n_epochs):
# model_pl.model.train()
# loss = model_pl.training_step(batch, None)
# loss.backward()
# optimizer.step()
# train_loss.append(loss.item())
# if not(epoch % 100):
# print(loss.item())# print(ds.from_tokens(model_pl.predict(idx=torch.zeros((1,1), dtype=torch.long), max_new_tokens=500)[0].tolist()))